Bulldog Puppy Sitting With Owner On Sofa Whilst He Works On Laptop
В этой статье я с точки зрения бизнес-аналитика расскажу, в каких ситуациях лучше использовать нереляционные базы данных и с чем они вам помогут.
Для начала предлагаю разобраться с термином NoSQL. Может показаться, что речь идет об отсутствии SQL-запросов, но это заблуждение. С нереляционными базами данных можно общаться и с помощью привычных реквестов. Поэтому NoSQL фактически означает “Not only SQL”.
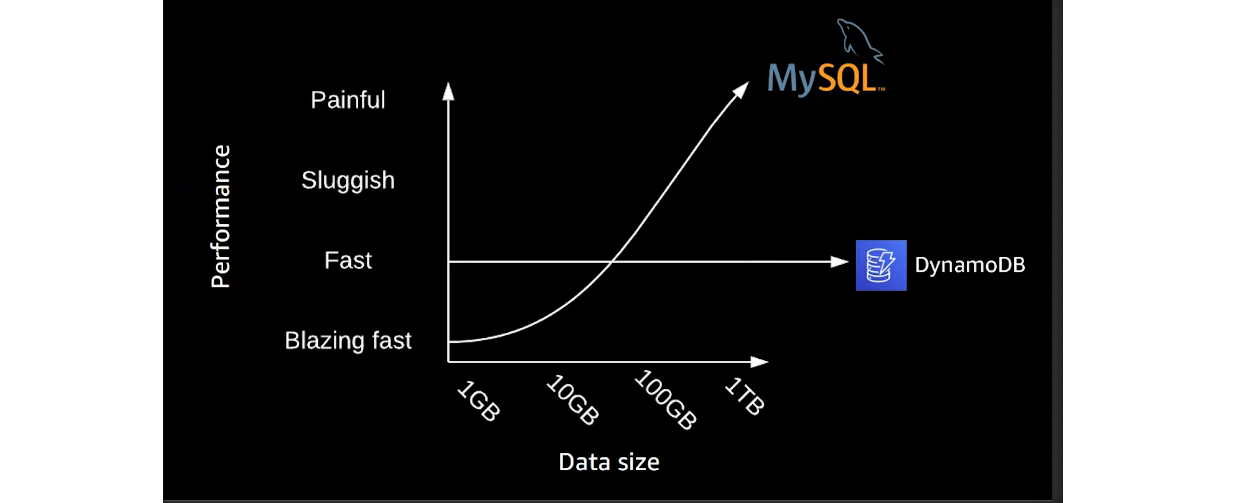
Необходимость введения отличной от SQL базы данных назревала давно. Последние 15 лет объемы данных стремительно растут. Например, Instagram в свое время вышел на уровень загрузки около 1000 фотографий и пересылки 8500 сообщений в секунду. Сегодня эти показатели в разы выше. Если обрабатывать значительные ресурсы данных классическими методами реляционных баз данных, система в конце концов остановится.
В определенный момент масштабирование SQL-баз попыталось решить технологией шардирования. В результате есть фактически несколько разных БД. А это совсем другая схема работы. Однако хуже другое – связи между образованными шардами не работают. Их невозможно масштабировать в принципе. С нереляционными базами таких проблем нет. Они стабильны с любым объемом данных.
Традиционный подход к хранению и обработке данных описывает аббревиатура ACID:
В контексте сравнения с NoSQL я сделал бы акцент на согласованности. Когда вы обращаетесь к данным в SQL, то уверены в их актуальности. Здесь вы не сможете читать и просматривать данные одновременно. Теоретически это возможно, но напоминает чтение книги параллельно ее написанию. Вы будете видеть сырые данные. Поэтому в реляционной модели данные всегда согласованы. Этот момент как раз ограничивает масштабирование.
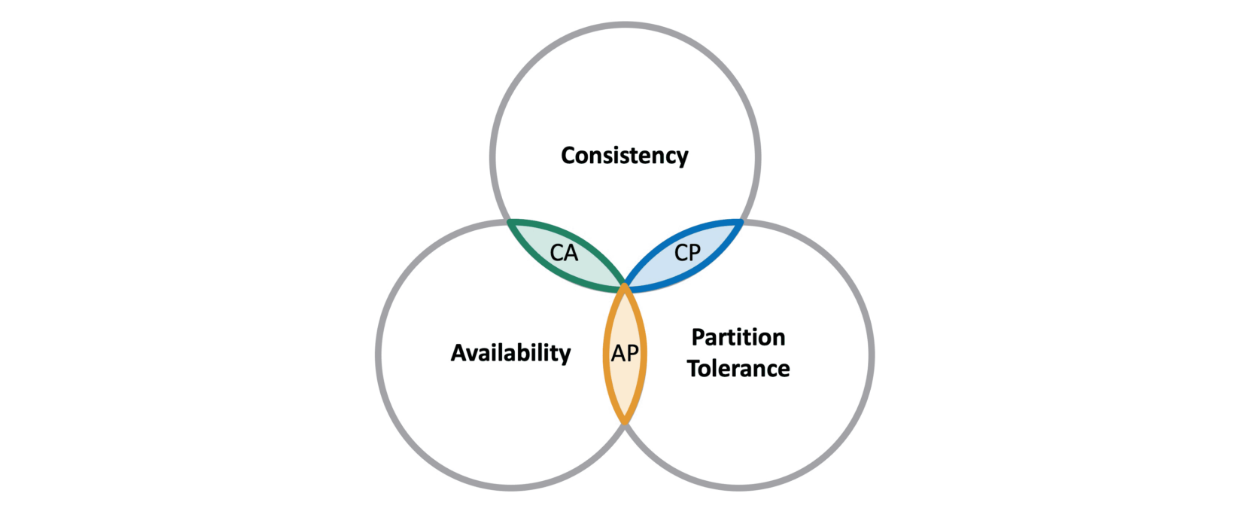
В архитектуре NoSQL работает другой подход – CAP:
Согласованность есть, без нее нет смысла в хоть какой БД. Однако требования менее жесткие.
Главный принцип нереляционной модели – данные распределяются между серверами. Таким образом удается масштабирование, но это приведет к нарушению целостности данных. Обращаясь к серверу, в котором данные еще не обновились, вы рискуете получить устаревшую информацию. В конце концов, лаг в актуализации реплик есть и в реляционной модели. Опыт показывает, что задержка обновления в NoSQL выше, но с каждым днем разница сокращается. В настоящее время нереляционные базы декларируют Eventually Consistency. В частности, DynamoDB заявляет о лаге 10 мс. Такой показатель доступен не всегда, но все равно отличный.
Как оказалось, бизнес готов пойти на такие риски ради преимуществ NoSQL. Рассмотрим это на примере банковских транзакций. Согласованность данных здесь считается критически важной. На самом же деле банки идут на послабление. Их базы данных огромны. Потребуется много времени на обработку тысяч одновременных запросов от пользователей банкинга. Если ставить их в очередь на сверку (например, при выдаче денег в банкомате), люди могут не дождаться реакции.
Поэтому банки переходят на другую модель обработки данных. Они сверяются с одним сервером, выдают деньги и убеждаются в согласованности данных по всей базе. Если два человека действительно одновременно захотят снять все деньги с одного счета, они их получат по сути дважды. Банк уже потом разберется с этой ошибкой. Ведь на самом деле вероятность попадания двух запросов в этот микролаг минимальна. Банку дешевле покрыть такой риск, чем слушать раздражение тысяч пользователей из-за длительной обработки транзакции.
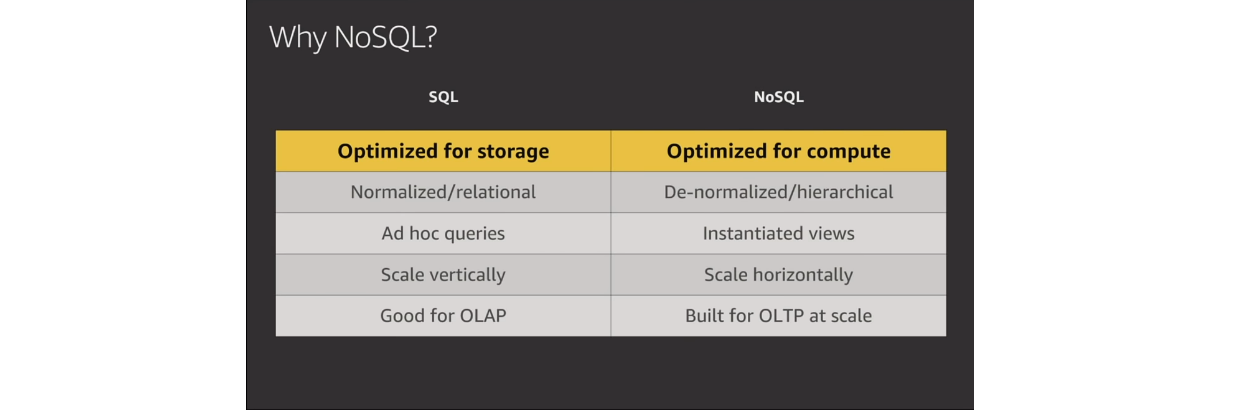
Кроме согласованности, есть разница и в доступе к данным. Для бизнес-аналитика это важный момент, в частности во время проведения OLAP-анализа. Реляционная БД больше подойдет для выполнения сложных запросов, оценки данных с разных сторон и построения прогнозов. Хотя в бизнесе мы можем предусмотреть до 80-90% шаблонов доступа, которые будут описывать возможные запросы. Это подразумевает OLTP-подход, соответствующий нереляционной БД.
В NoSQL следует делать только те запросы, которые в принципе эффективно выполнять. Возможность запроса должна быть заложена при проектировании базы. В противном случае системе придется сканировать всю БД. Это сводит на нет все преимущества скорости обработки запросов.
Что мы имеем: реляционные базы идеальны для хранения нормализованных данных, а нереляционные — оптимальные для вычислений, особенно облачных. Это вполне отвечает современным требованиям к архитектуре приложений и очень удобно в работе.
Существует более 200 NoSQL баз пятнадцати типов. Две трети из них приходится на четыре основные категории. Остановлюсь подробнее на каждой:
Каждый тип NoSQL имеет свои особенности. Я остановлюсь на Key-Value как наиболее распространенной нереляционной базе данных. Тем более эта база есть в одном из моих проектов – а именно DynamoDB. Ее выбор, как и любой другой базы, сложно до конца назвать рациональным. На конечное решение влияет множество факторов: от бизнес-требований до пожеланий заказчика. Хотя это не отменяет попытки осознанной оценки проекта.
Выбрав нужный тип БД, переходите к проектированию. В случае NoSQL мы ограничены в способах доступа к данным. Поэтому необходимо настроить модель под частые и важные запросы. Для этого подробно разберите Use Cases и все требования к продукту. Так вы сможете правильно оценить, как посмотреть на ваши данные. Это и станет основой для будущей структуры данных.
В следующей части статьи я расскажу, как смоделировать базу данных на примере DynamoDB. Следите за обновлениями 😉
В благословенные офисные времена, когда не было большой войны и коронавируса, люди гораздо больше общались…
Вот две истории из собственного опыта, с тех пор, когда только начинал делать свою карьеру…
«Ты же программист». За свою жизнь я много раз слышал эту фразу. От всех. Кто…
Отличные новости! Если вы пропустили, GitHub Copilot — это уже не отдельный продукт, а набор…
Несколько месяцев назад мы с командой Promodo (агентство инвестировало в продукт более $100 000) запустили…
Пару дней назад прочитал сообщение о том, что хорошие курсы могут стать альтернативой классическому образованию.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}