Содержание
Сегодня мы рассмотрим важный инструмент для взаимодействия с базами данных — Hibernate. Вы узнаете что это за библиотека, в каких случаях и как используется, а также как реализована работа с БД в Java.
Но перед тем, как перейти к разговору о самом Hibernate, нужно сказать пару слов о том, что означает ORM, JDBC и некоторых принципах работы с БД.
Когда Java-программа устанавливает связь с базой данных, она не посылает запросы к таблицам напрямую, а использует программный интерфейс JDBC (Java Database Connectivity). Подключение к БД и дальнейшее взаимодействие с ней происходит через специальные драйверы. Вместо того, чтобы создавать отдельный набор методов и процедур, которые будут работать с конкретной базой данных (как например, это сделано в PHP — где есть отдельные наборы процедур для MySQL, Postgres и прочих БД), в Java был придуман единый интерфейс.
Он позволяет любой Java-программе иметь дело с разными реляционными базами через абсолютно одинаковые методы. Чтобы в каждом случае работа шла с едиными методами, должны быть задействованы JDBC-драйверы. Динамически подгружаясь по ходу выполнения приложения, такой драйвер автоматически инициализируется и вызывается, когда приложение запрашивает URL, включающий протокол, за который ответственен драйвер.
Код обычного драйвера JDBC MySQL под платформу Linux имеет вид:
package javaapplication1;
import java.sql.*;
public class Main {
public static void main(String[] args) throws SQLException {
/**
* Этот код выполняет загрузку драйвера DB.
*/ //Class.forName("com.mysql.jdbc.Driver");
Connection conn = null;
try {
conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/db_name",
"user", "password");
if (conn == null) {
System.out.println("Отсутствует коннект с БД!");
System.exit(0);
}
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
while (rs.next()) {
System.out.println(rs.getRow() + ". " + rs.getString("firstname")
+ "\t" + rs.getString("lastname"));
}
stmt.close();
}
catch (SQLException e) {
e.printStackTrace();
} finally{
if (conn != null){
conn.close();
}
}
}
} При переключении с одной БД на другую, работа Java-программы никак не меняется, что выгодно отличает эту реализацию от, скажем, языка PHP, где переход с одной БД на другую требует от разработчиков переписывания целого слоя работы с базой данных (с использованием других методов).
Обязанность по созданию JDBC-драйвера лежит на вендоре базы данных. К любой БД такой драйвер уже существует и поддерживается разработчиком, его легко можно найти в интернете.
Набор операций JDBC стандартный и очень простой:
statement;select.Существует ряд фундаментальных проблем, связанных с работой языка Java с реляционными БД. Язык Java использует парадигму ООП, поэтому мы все время имеем дело с объектами. В то же время реляционные базы данных оперируют таблицами.
Объекты в Java и таблицы в БД — это разные сущности, которые сложно между собой сопоставить. С другой стороны, для решения задач нам постоянно нужно каким-то образом объекты превращать в таблицы и наоборот. Задача нетривиальная, решить которую сложно — нужно писать некоторую логику, используя тот же самый JDBC.
Преимущества JDBC:
Недостатки JDBC:
В простых случаях применять JDBC не сложно (например, был объект «Пользователь», и для того, чтобы записать его в базу данных, мы из некоторой строки достаем id, имя и т.д.). Но если мы будем иметь дело со сложным графом объектов, сохранить его в базу данных будет уже не так легко — придется писать длинный код SQL, который потом проверить будет очень сложно. Кроме того, мы имеем дело в Java классом based object oriented language, где есть наследование, а в таблицах нет никакого наследования.
Если вы пишете серьезное приложение, то вы будете работать с кодом на огромное число строк. Вся современная бэкенд-разработка — это работа с большим количеством информации. Как следствие — разработчик имеет дело с постоянными запросами к БД. Ему необходимо чуть ли не в каждой строчке написать connect, получить, извлечь данные из базы, затем строки и цифры нужно разложить по полям объектов. Серьезный enterprise-объект может содержать до десяти тысяч полей и, соответственно, у вас будет десять тысяч строк. Ситуация осложняется тем, что такие объекты постоянно меняются — по этой причине приходится решать массу проблем.
Объектная модель данных и модель данных в реляционных таблицах не очень совпадают. Имеется некая логика сравнения объектов, и никто не гарантирует, что эта логика совпадает и в базе данных, и в приложении. Это может приводить к большому числу ошибок.
Например, вы создали нового пользователя, поместили его в базу данных, а затем вдруг оказалось, что в базе данных он считается другим пользователем из-за того, что там критерии сравнения другие.
Мы обязаны следить, чтобы в объектной модели Java и той, которая хранится в базе, сущности совпадали, чтобы была одна и та же логика сравнения.
В объектной модели данных Java также имеются некие дополнительные возможности — например, разные уровни доступа к разным полям. Некоторые поля мы бы не хотели иметь в БД, некоторые мы бы не хотели извлекать или записывать.
Чтобы не кодить лишний раз и думать про JDBC, была взята концепция ORM.
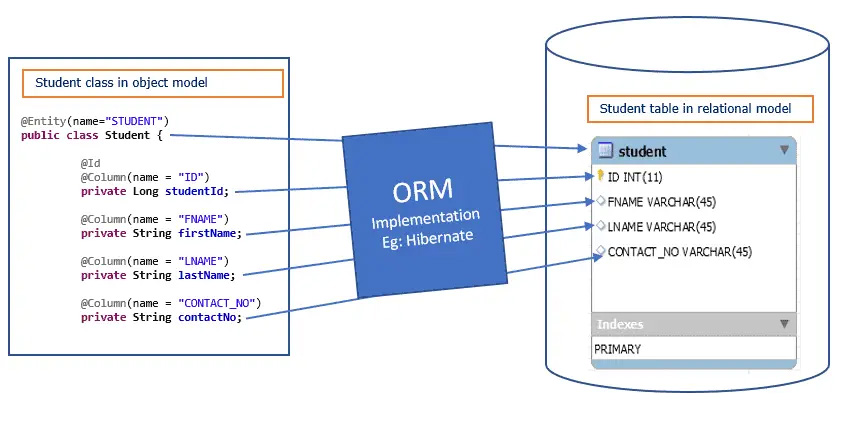
Object-Relational Mapping — это механизм, который позволяет отображать данные из реляционных баз данных в виде объектов. ORM-системы упрощают работу с базами данных, уменьшая необходимость руководствоваться SQL-командами.
В Java присутствует спецификация JPA (Java Persistence API). Она определяет способы для управления данными и содержит инструменты:
insert, select и пр.), стандартных операций (создание, чтение, обновление и удаление).Чтобы реализовать JPA нам понадобится так называемые JPA-провайдеры — библиотеки, которые его реализуют.
Таких провайдеров существует много для разных языков программирования:
Более половины имплементаций JPA выполнено на фреймворке Hibernate с открытым кодом, чем объясняется популярность этой библиотеки.
Hibernate прямо в программном коде с помощью дополнительного конфигурационного файла или аннотаций на полях определяет, какое поле соотносится с каким полем в базе данных.
Другими словами: производится объектно-реляционный мэппинг (ORM). Благодаря Hibernate (который использует программный интерфейс JDBC) программисты не задумываются, как поля из базы данных попадают в поля объектов.
Для работы Hibernate использует HQL — эквивалент языка SQL, только с учетом Java-классов. Фреймворк может применяться в любом типе приложений — desktop/web, Spring и так далее. Сегодня Hibernate портирован на другие языки, например, в C# (.NET) используется Nhibernate.
Еще одна из особенностей Hibernate — механизм «ленивой загрузки». Он позволяет отложить загрузку связанных сущностей, пока они не будут явно использованы. Отложенные SQL-запросы будут выполняться только тогда, когда связанные сущности (ключи) будут явно использованы.
Подведем итог. Hibernate применяется в Java-разработке, когда возникает необходимость перенести из базы данных информацию в код и как-то ее обработать. Этот фреймворк помогает оптимизировать низкоуровневый код, ускорив его написание и сделав его более компактным и удобным для разработчиков.
Схема работы нашего приложения выглядит, примерно, следующим образом:
Программа общается с базой данных посредством Hibernate через JDBC-коннектор, используя конфигурацию conf. В этих конфигурационных параметрах указано, как Hibernate должен передавать данные.
Представление Java-классов с таблицами БД реализуется посредством XML-файлов с конфигурациями либо через Java-аннотации.
Когда данных много, связи между сущностями добавляют головной боли. В Hibernate есть стандартный набор связей, которые могут понадобиться:
Перед тем, как приступить к работе с Hibernate, вам нужно изучить:
Обычно, для создания любого приложения в Hibernate необходимо выполнить следующие действия:
1. Создать проект и подключить зависимости.
2. Добавить параметры для работы Hibernate.
3. Выполнить представление (мapping) классов для связывания таблиц БД с кодом.
4. Создать SQL-запросы для бизнес-процессов (select, update, delete и т.д.)
5. Обработать результаты запросов.
6. Представить результаты в нужном формате во внешнем графическом интерфейсе (web, Android, десктопное приложение и т.д.).
Один из способов оптимизации и ускорения работы приложения — кэширование.
В Hibernate используется три уровня кэшей:
persistence context. Допустим, вы хотите выгрузить сущность из БД. Она выгружается один раз и попадает в persistence context. Вы тут же хотите выгрузить еще раз, и Hibernate уже не обратится к БД, а возьмет из persistence context. При работе с этим типом кэширования нередко возникают сайд-эффекты. Например, он хорошо работает через EntityManager. Но бывает так, что если вы меняете сущности вне EntityManager, кто-нибудь в другой транзакции обращается к БД и меняет сущность. В первой транзакции она выгружена и, если вы захотите проверить, является ли она подходящей под ваши параметры, сущность уже будет иной. Вам про это будет неизвестно, потому что у вас будет задействован кэш первого уровня.Hibernate, безусловно, удобен. Самые популярные IDE (среды разработки) поддерживают этот фреймворк через плагины. Но хотя библиотека и помогает нам убрать «спагетти» из кода, упростив его, она все же имеет ряд недостатков:
В Hibernate часто встречаются конфигурации по умолчанию — имена таблиц, столбцов и т.д. Кроме того, для некоторых параметров фреймворк сам «догадывается» про требуемое значение.
Например, вы можете забыть сделать аннотацию и Hibernate может сам попробовать связать сущности через дополнительную таблицу. При этом он сделает предположение, как именно должна называться эта промежуточная таблица.
Поскольку у Hibernate — не одна библиотека, а несколько, следует их все подключить. Наш проект будем использовать со сборщиком Maven, который будет отвечать за загрузку необходимых нам библиотек.
pom.xml, содержащий информацию о зависимостях и прочие опции. Внутри папки java будем писать java-классы, в папке resources будут находится все файлы конфигурации Hibernate.
Файл pom.XML выглядит так:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.app.HibernateTest</groupId> <artifactId>QuickStart</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>19</maven.compiler.source> <maven.compiler.target>19</maven.compiler.target> </properties> </project>
В разделе зависимостей (dependency) мы должны указать, что мы будем работать с Hibernate:
pom.xml:
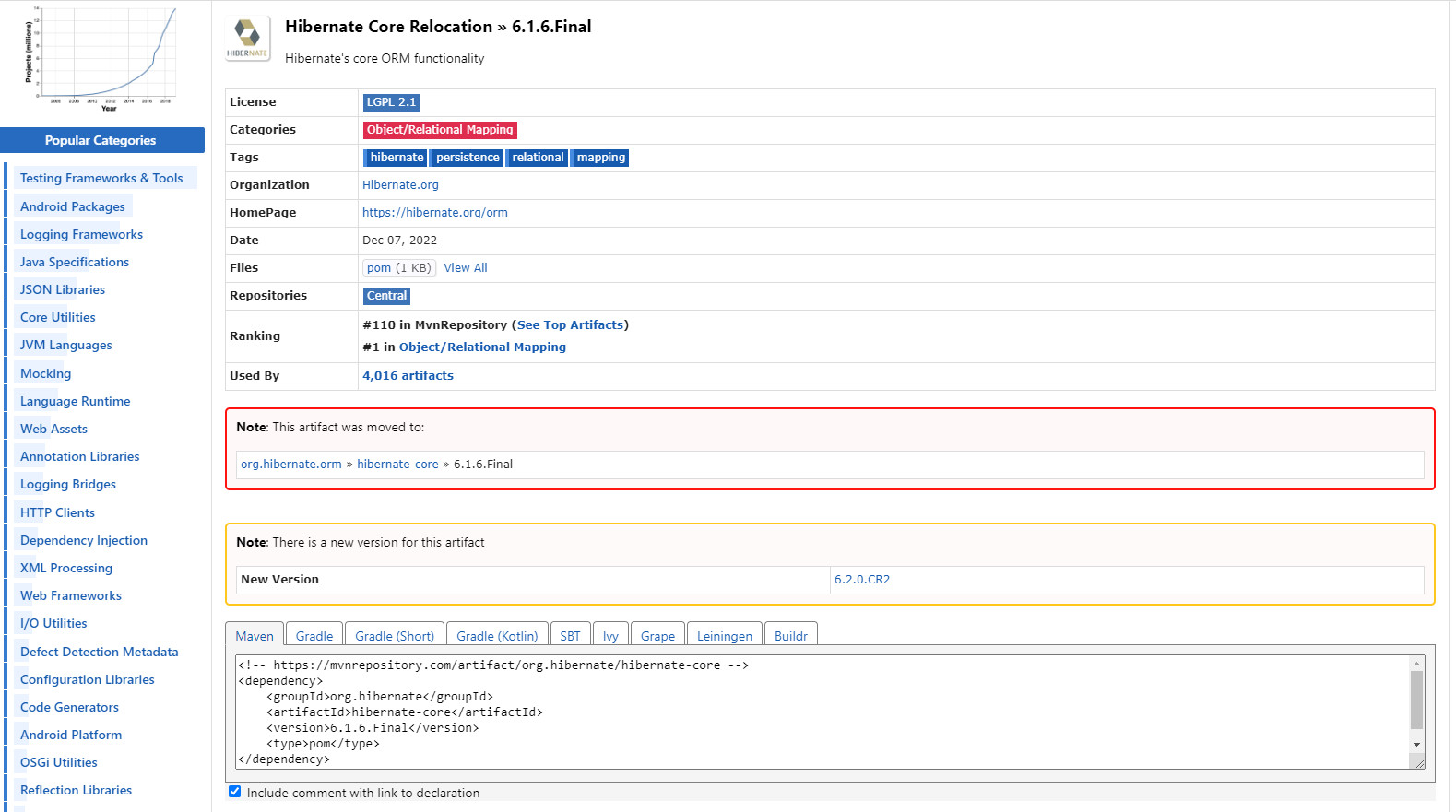
<!-- https://mvnrepository.com/artifact/org.hibernate/hibernate-core --> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> <version>6.1.6.Final</version> <type>pom</type> </dependency>
Далее по поиску в репозитории ищем соответствующие зависимости для коннектора БД и вставляем их тоже:
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.32</version> </dependency>
Принципиального значения, какую брать версию — нет, но вы должны понимать, что если что-то не работает или работает не так, как хотелось, возможно, следует попробовать другую. К сожалению, часто возникают ошибки.
Создадим класс Student, содержащий поля, которые нужно промапить. Добавим публичный конструктор и переопределим метод:
package com.app.pojo;
public class Student {
private int id;
private String name;
private int age;
public Student(){}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
} Перед началом работы с базой пропишите параметры в файле hibernate.cfg в каталоге resources. Есть еще альтернативный вариант с xml-настройками — через файл persistence.xml. Он применяется для любой реализации JPA (в том числе и Hibernate), но он, понятное дело, ограничен спецификацией JPA.
Создадим hibernate.cfg:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <!-- Version 8 MySQL hiberante-cfg.xml example for Hibernate 5 --> <hibernate-configuration> <session-factory> <property name="connection.driver_class">com.mysql.cj.jdbc.Driver</property> <!-- property name="connection.driver_class">com.mysql.jdbc.Driver</property → //Указываем, где искать драйвер; <property name="connection.url">jdbc:mysql://localhost:3306/mydb</property> //Путь, по которому будет идти запрос при обращении к базе данных (для данного примера - testdatabase на порту 3306, имя БД - mydb) <property name="dialect">org.hibernate.dialect.MySQL8Dialect</property> <property name="connection.username">root</property> //Пользователь <property name="connection.password">root</property> //Пароль <property name="connection.pool_size">3</property> <!--property name="dialect">org.hibernate.dialect.MySQLDialect</property→ //Диалект для БД, к которой будет идти подключение; <property name="current_session_context_class">thread</property> <property name="show_sql">true</property>//отображение SQL-запросов; <property name="format_sql">true</property> <property name="hbm2ddl.auto">update</property> //Поле, необходимое для того, чтобы дать разрешение Hibernate на обновление данных в БД. Если данных не будет, он их создаст. <!-- mapping class="com.mcnz.jpa.examples.Player" / --> </session-factory> </hibernate-configuration>
Внутри конфигурационного файла создается секция session-factory — фреймворк открывает сессию, в течение которой делает запросы. Как только сессия будет закончена, он ее будет закрывать. Порядок свойств (property) в конфигурационном файле не имеет значения.
Для получения сессии можно использовать два главных объекта — SessionFactory (в JPA — EntityManagerFactory) и Session (в JPA — EntityManager). SessionFactory создается только один раз при запуске приложения, он настривать, работать с сессиями. При создании SessionFactory считываются параметры hibernate.cfg.xml.
Создадим еще один класс — наше Java-приложение App. Id для студента создавать не будем, этот идентификатор будет автоматически создаваться в БД одновременно с появлением новой записи.
Обратите внимание: уникальный ключ должен быть всегда, если мы его создаем, в БД он создаваться не должен, иначе в базе данных будут ошибки.
Мы хотим передать данные нашего студента в таблицу. Соответственно, нам желательно было бы написать что-то простое, например save(Serge):
package com.app;
import com.app.pojo.Student
import org.hibernate.cfg.Configuration;
public class App {
public static void main(String[] args) {
Student Serge = new Student();
Serge.setName("Serge");
Serge.setAge(10);
//Serge.setId();
Configuration con = new Configuration().configure;
con.addAnnotatedClass (Student.class);
StandardServiceRegistryBuilder sBilder = new StandardServiceRegistryBuilder()
.applySettings(con.getProperties());
SessionFactory sf = con.buildSessionFactory(sBilder.build());
}
} Если это необходимо, в конфигурационном файле мы можем написать, сколько фабрика сессий может генерировать потоков для работы с клиентами. После того, как фабрика сессий прописана, можем переходить к CRUD.
Начнем с команды Create:
public class App {
public static void main(String[] args) {
Student Serge = new Student();
Serge.setName("Serge");
Serge.setAge(10);
//Serge.setId();
Configuration con = new Configuration().configure;
con.addAnnotatedClass (Student.class);
StandardServiceRegistryBuilder sBilder = new StandardServiceRegistryBuilder()
.applySettings(con.getProperties());
SessionFactory sf = con.buildSessionFactory(sBilder.build());
//create
Session sessionCreate = sf.openSession();
Transaction trCreate = sessionCreate.beginTransaction;//Начало транзакции
sessionCreate.save(Serge);
trCreate.commit();
sessionCreate.close();//Завершение транзакции
}
} Напомним, транзакции позволяют сохранять состояние базы данных. Они удостоверяют, что изменения, сделанные в рамках транзакции, сохранятся, или, наоборот — изменения, сделанные в рамках транзакции, будут отклонены.
Поэтому между созданием и коммитом транзакции мы можем сохранять сразу несколько объектов. Посмотрим, как работает теперь наше приложение. Возьмем базу данных (принципиального значения, что это будет за БД не имеет), подключимся к ней и посмотрим на результат:
Serge. Значение id присвоено автоматически. При повторном добавлении пользователя автоматически присваивается новый id. Помимо основной таблицы Hibernate создал также еще одну — hibernate_sequence. Это промежуточная таблица, в которой хранится инкрементируемое значение value.
Транзакция прошла, данные добавлены. Переходим к команде Read и открываем новую сессию:
//read Session sessionRead = sf.openSession(); Transaction trRead = sessionRead.beginTransaction(); Student student1 = sessionRead.find(Student.class, o:1); System.out.println(student1.toString()); trRead.commit(); sessionCreate.close();
Результат вывода в консоль:
Student{id=1, age=10, name=Serge}
Следующая команда Update:
//update
Session sessionUpdate = sf.openSession();
Transaction trUpdate = sessionUpdate.beginTransaction();
Student student2 = sessionUpdate.find(Student.class, o:2);
student2.setAge(20);
student2.setName("Alexander");
sessionUpdate.update(student2);
trUpdate.commit();
sessionUpdate.close(); Пользователь в базе данных обновит свое имя и значение Age.
Последняя транзакция — Delete:
//delete Session sessionDelete = sf.openSession(); Transaction trDelete = sessionDelete.beginTransaction(); sessionDelete.delete(student2); txDelete.commit(); sessionDelete.close();
Запись в таблице будет уничтожена.
Hibernate — это удобный, мощный и эффективный ORM-фреймворк. Он прост в изучении и существенно экономит время при разработке ПО, в котором идет обращение к базам данных. Используя его, программист может сосредоточиться на основной логике, сократив написание запросов к минимуму.
Как видите, в приложении Hibernate нет ничего сложно. Главная трудность, с которой вам придется столкнуться — правильная настройка зависимостей и конфигурационных файлов проекта. Также важно правильно пользоваться инструментами для автоматизации сборки проектов: Mavеn, Gradle и другими.
Ссылки с конфигурациями в репозиториях постоянно меняются, поэтому будьте внимательны и, если что-то не работает — проверьте их актуальность.
Стабильность работы приложения на Hibernate во многом зависит от версии Java и используемых модулей (например, Hibernate 6.1.3 с Java 17 вызывает ошибки, а та же версия, но уже с Java 18 работает нормально).
В заключение рекомендуем посмотреть замечательный курс по основам работы Hibernate:
Visual Code от Microsoft, вероятно, один из самых популярных редакторов кода. Разработчики любят его за…
Япония сама по себе — сплошной киберпанк. Это заметил даже культовый писатель жанра Уильям Гибсон,…
Сам по себе телефон Айфон 17 Про Макс – отличный подарок. У него красивая заводская…
На фоне роста спроса на ликвидность в бычьем рынке 2025 года, криптозаймы снова выходят на…
Прокси (proxy), или прокси-сервер — это программа-посредник, которая обеспечивает соединение между пользователем и интернет-ресурсом. Принцип…
Согласитесь, было бы неплохо соединить в одно сайт и приложение для смартфона. Если вы еще…
{kind=link}
{kind=link}
{kind=link}