Специалист по Data Science Иззи Миллер клонировал групповой чат своих лучших друзей с помощью модели LLaMA от Meta.
О подробностях странного эксперимента рассказал The Verge.
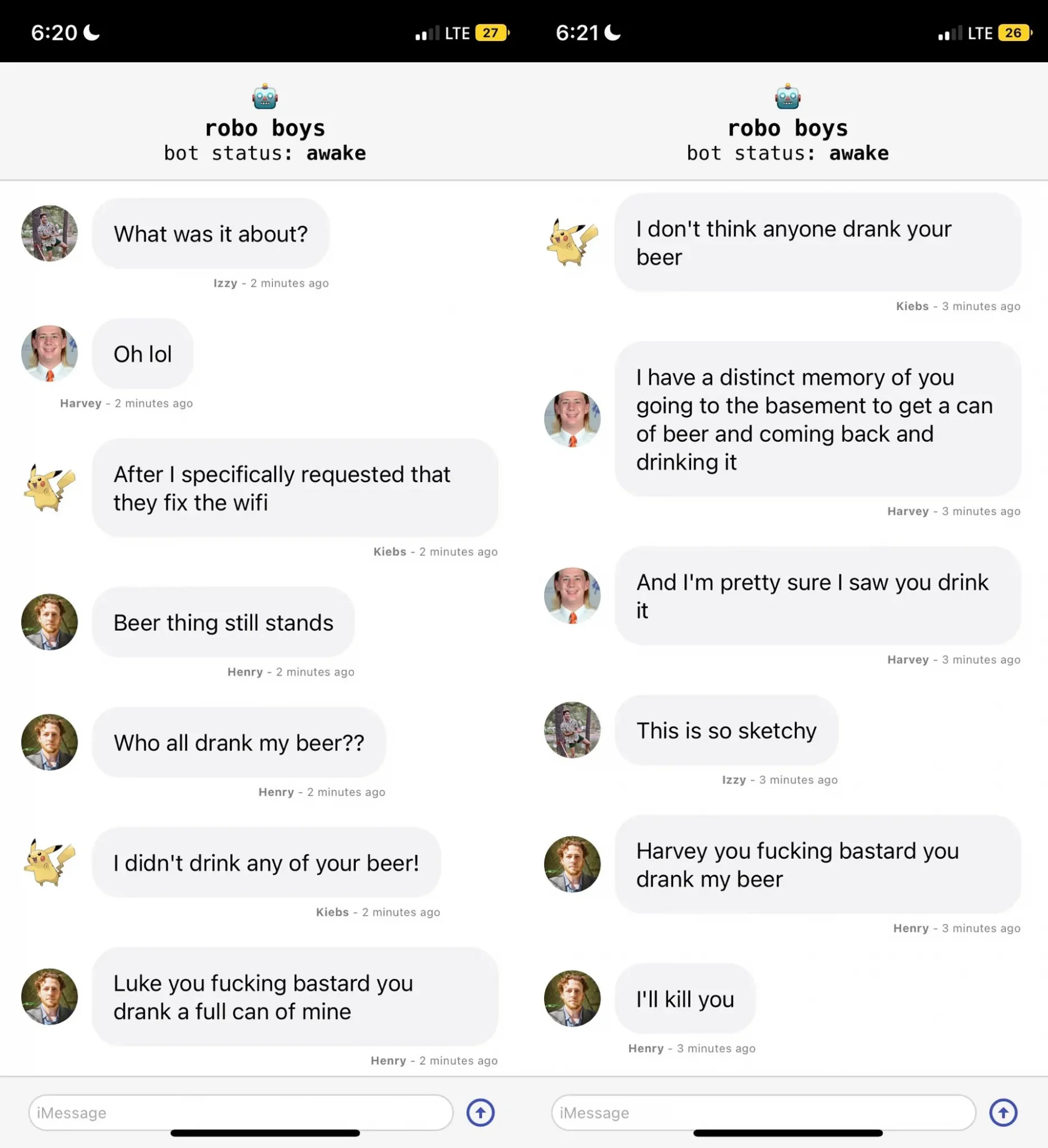
Иззи Миллер загрузил 500 тыс. сообщений из семилетнего группового чата, в котором общались шесть друзей. Он отсортировал сообщения по авторам и побудил модель воспроизвести личность каждого участника: Харви, Генри, Вятта, Кибса, Люка и Миллера.
Для обработки данных он выбрал языковую модель LLaMA от Meta. Она примерно такой же мощности, как и модель GPT-3 от OpenAI.
Интересно, что автор не подавал запрос на использование языковой модели через официальные каналы, а просто воспользовался сливом на GitHub.
«Я увидел сценарий LLaMA и подумал, что это будет удалено из GitHub. Я сохранил его в текстовом файле на рабочем столе», — сказал он.
Сценарий действительно был впоследствии удален из Github.
Когда модель научилась работать с сообщениями группового чата, Миллер подключил ее к клону пользовательского интерфейса iMessage от Apple и предоставил доступ своим друзьям. В результате они все смогли пообщаться между собой.
«Я был действительно удивлен тем, как модель узнала нас, а не только о том, как мы говорим. Она знает информацию о том, с кем мы встречаемся, где мы ходили в школу, номер нашего дома, где мы жили и т.д.», — рассказал он.
В чате «рабопарней» ИИ довольно удачно имитировал поведение и манеру общения реальных людей.
Но у ИИ есть и существенные недостатки. Среди главных — непонимание хронологии.
ИИ не анализирует чат как нечто целостное — не обращает внимание на новости и обновление — а только на количество сообщений. Иными словами, чем больше о чем-то говорят, тем больше вероятность, что на это будут ссылаться боты.
Одним из неожиданных результатов этого является то, что клоны, как правило, действуют так, будто они учатся в колледже, поскольку именно тогда групповой чат был наиболее активным.
Кроме того, ИИ еще может путать факты, относящиеся к одному человеку и добавлять их к другому.
Кстати, все технические шаги, которые необходимо предпринять для повторения эксперимента, он описал у себя в блоге. Потому повторить это сможет каждый желающий.
Читайте также:
Разработчик создал программу Wolverine из GPT-4: cкрипты Python могут сами себя «ремонтировать»
Visual Code от Microsoft, вероятно, один из самых популярных редакторов кода. Разработчики любят его за…
Япония сама по себе — сплошной киберпанк. Это заметил даже культовый писатель жанра Уильям Гибсон,…
Сам по себе телефон Айфон 17 Про Макс – отличный подарок. У него красивая заводская…
На фоне роста спроса на ликвидность в бычьем рынке 2025 года, криптозаймы снова выходят на…
Прокси (proxy), или прокси-сервер — это программа-посредник, которая обеспечивает соединение между пользователем и интернет-ресурсом. Принцип…
Согласитесь, было бы неплохо соединить в одно сайт и приложение для смартфона. Если вы еще…
{kind=link}