Hi-Tech futuristic user interface head up display screen with digital data and information display for digital background. Computer desktop display screen concept
Неможливо достеменно знати, що відбувається всередині віддаленої чи розподіленої системи, навіть якщо вони запущені на локальному ПК. Саме телеметрія надає всю інформацію про перебіг внутрішніх процесів. Ці дані можуть бути у вигляді логів, метрик або Distributed Trace.
У блозі розповім окремо про кожен із цих форматів, а також розглянемо, чим корисний протокол OpenTelemetry та як ви можете гнучко налаштувати телеметрію.
Велика IT-система та навіть деякі види бізнесу не зможуть існувати без телеметрії. Тому цей процес треба підтримувати та впроваджувати в проєкти, якщо його немає.
Найпростіший тип даних у телеметрії. Логи бувають двох типів:
Зазвичай логувати всі дані непотрібно. Оцініть систему, знайдіть (якщо досі цього не зробили) найбільш вразливі та цінні частини системи. Скоріш за все, там треба додати логів. Іноді вам треба буде використовувати логорієнтоване програмування. У моїй практиці був проєкт десктопного застосунку на WPW, який погано працював із потоками. Єдиний шанс побачити, що відбувалося — логувати кожен крок.
Більш складні дані у порівнянні з логами. Можуть бути цінними і для команди розробки, і для бізнесу. Метрики також виділяють автоматичні та мануальні:
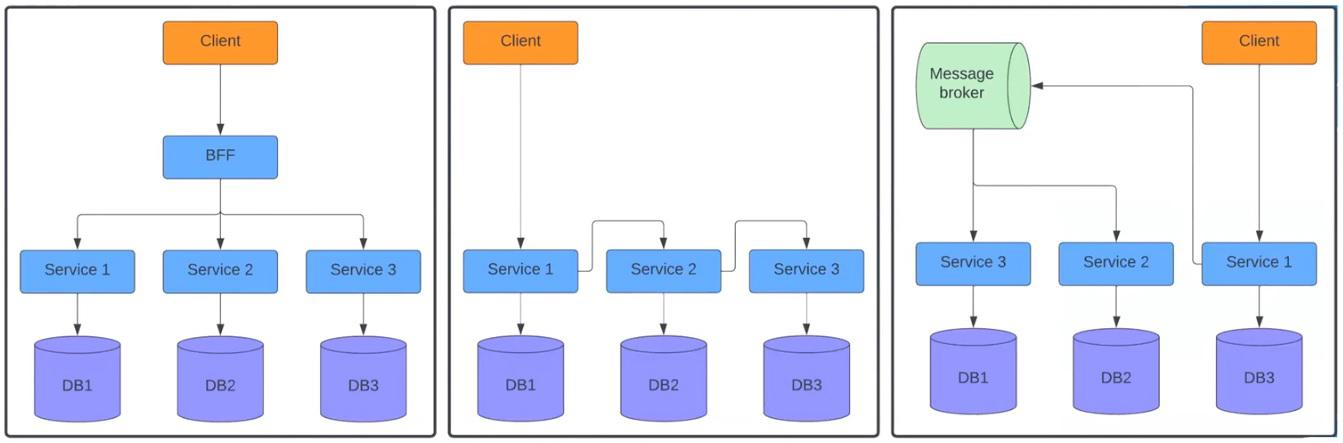
Ці дані необхідні для роботи з розподіленими системами, що знаходяться не на одному інстансі. Тобто ми не знаємо, котрий інстанс та якого сервісу обробляє той чи інший реквест у певний проміжок часу. Все залежить від побудови системи. Тут можливі такі варіанти:
На першій схемі ліворуч клієнт надсилає реквест до BFF, а той — окремо до трьох сервісів. У центрі показана ситуація, коли реквест надходить до першого сервісу, який відправляє його до другого, а той вже до третього. Схема праворуч зображує, як сервіс надсилає реквести до Message Broker. Далі він розподіляє їх між другим і третім сервісами.
Думаю, ви стикалися з подібними системами, і прикладів можна навести безліч. Ці схеми дуже відрізняються від монолітів. У системах з одним інстансом нам відомий стек викликів від контролера до бази даних. Тому можна відносно легко знайти, де і що відбулося протягом певного API call. Скоріш за все цю інформацію надає фреймворк.
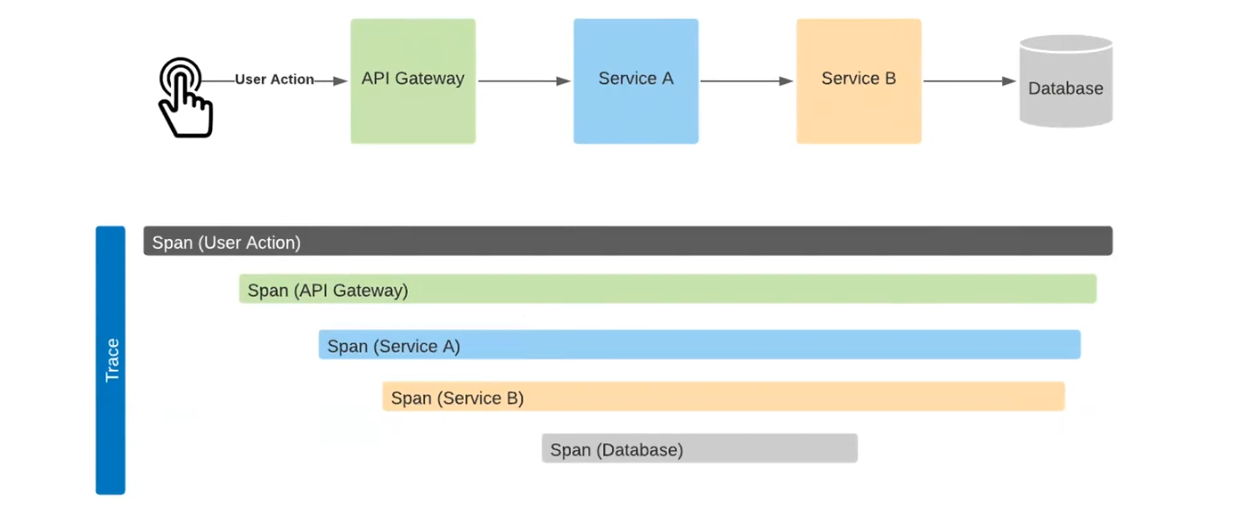
Та у розподілених системах неможливо побачити весь флоу. Кожен сервіс має окрему систему логування. Під час надсилання реквесту на BFF ми бачимо, що сталося всередині, але не знаємо, що відбувалося в сервісах 1, 2 та 3. Саме для такої ситуації придумали Distributed Trace. Ось приклад роботи:
Розберемо детально. Тут User Action йде на API Gateway, потім — на сервіс А, далі — на сервіс В. У результаті створюється виклик до бази даних. При їх надсиланні до системи на виході отримаємо подібну до наведеної схему.
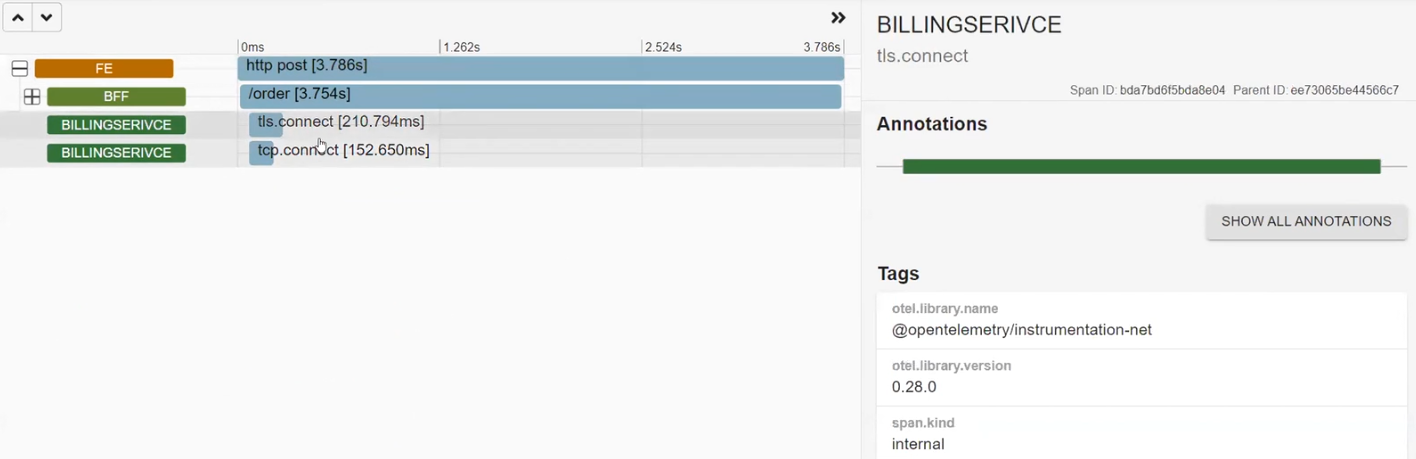
Тут добре видно тривалість кожного процесу: від User Action до Database. Наприклад, бачимо, що виклики йшли один за одним. Час між викликом API Gateway та Service A прийшовся скоріше на сетап HTTP-з’єднання. Час між викликом Service B та Database знадобився на сетап до бази даних та обробку цих даних. Тож можна оцінити, де і скільки часу витрачено на кожну операцію. Це можливо завдяки механізму Correlation ID.
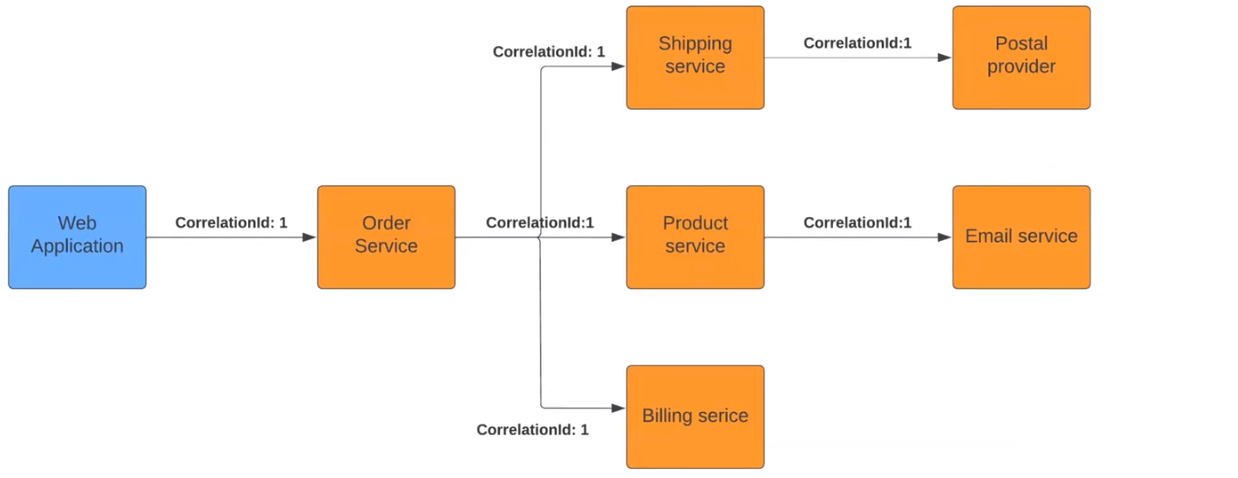
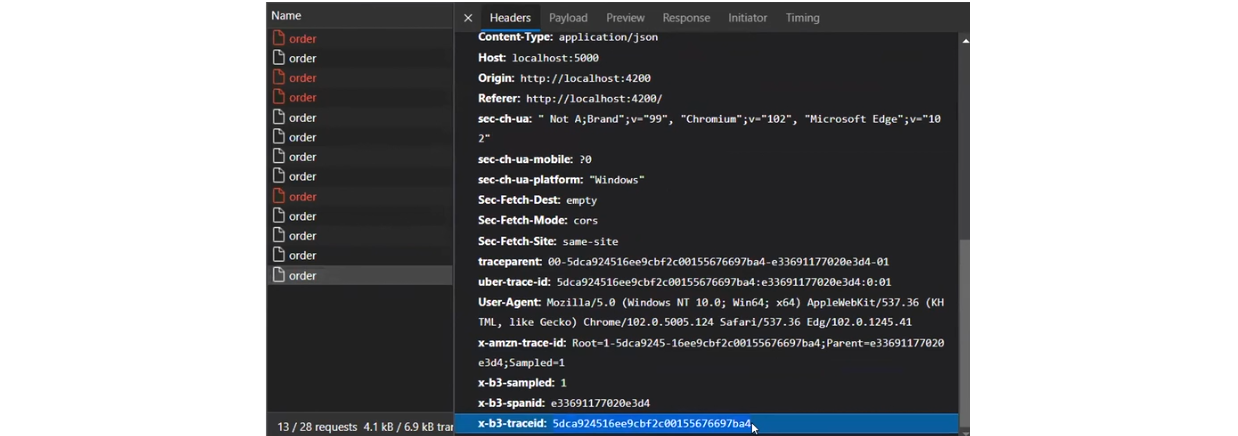
У чому суть? Зазвичай у монолітних застосунках при логуванні система прив’язує логи та екшени до process ID або thread ID. Тут механізм той самий, але ми його штучно додаємо до реквестів. Погляньмо на приклад:
При старті у Web Application екшену Order Service він бачить доданий Correlation ID. Так сервіс розуміє, що він є частиною ланцюжка, і передає «маркер» далі наступним сервісам. Вони зі свого боку розуміють себе як частину великого процесу. В результаті кожен елемент логуватиме дані так, щоб система бачила все, що відбувається протягом багатоетапного екшену.
Передача Correlation ID може відбуватися по-різному. Наприклад, у HTTP ці дані частіше за все передаються як один із параметрів хедерів. У сервісах Message Broker зазвичай записується всередині меседжу. Хоча, мабуть, у кожній платформі є SDK чи бібліотеки, що допоможуть реалізувати цей функціонал.
Часто формат телеметрії старої системи не підтримується в новій. Це призводить до багатьох проблем під час переходу з однієї системи на іншу. Наприклад, так було з AppInsight і CloudWatch. Дані не групуються, а отже щось працює не так.
OpenTelemetry дозволить обійти такі проблеми. Це протокол передачі даних у вигляді об’єднаних бібліотек OpenCensus та OpenTracing. Першу створювали розробники Google для збору метрик і трейсів, другу — фахівці Uber лише для трейсів. В якийсь момент компанії зрозуміли, що працюють фактично над однією задачею. Тому вирішили об’єднати зусилля і створити універсальний формат відображення даних.
Завдяки протоколу OTLP логи, метрики та трейси надсилаються в єдиному форматі. Згідно з репозиторієм OpenTelemetry, сьогодні відомі IT-гіганти контриб’ютять цей проєкт. Він має попит у продуктах, які збирають та відображають дані (наприклад, Datadog та New Relic). Також він є помічним у системах, яким потрібна телеметрія (Facebook, Atlassian, Netflix та інші).
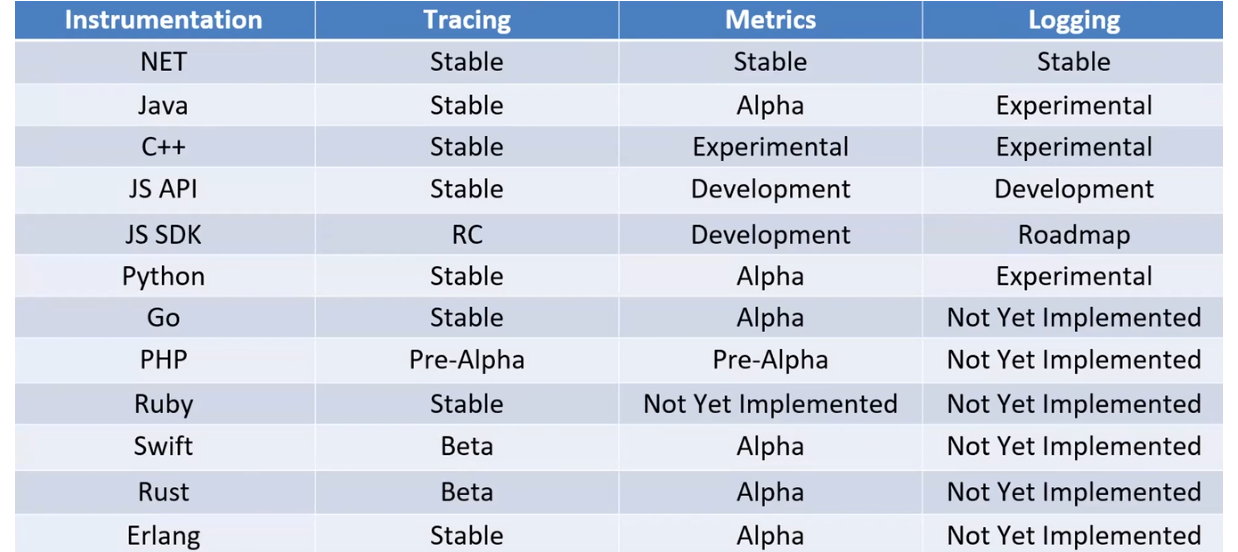
Існує багато SDK для популярних мов програмування. Проте всі вони мають різні можливості. Зверність увагу на таблицю. Трейсінг має стабільні версії усюди, крім PHP та JS SDK. А от з метриками та логами досі не дуже добре у багатьох мовах. Десь є лише альфа-версії, десь експериментальні, подекуди взагалі не реалізовано імплементацію протоколу. З власного досвіду скажу, що на сервісах на .NET все працює нормально. Тут і просте підключення, і надійність логування.
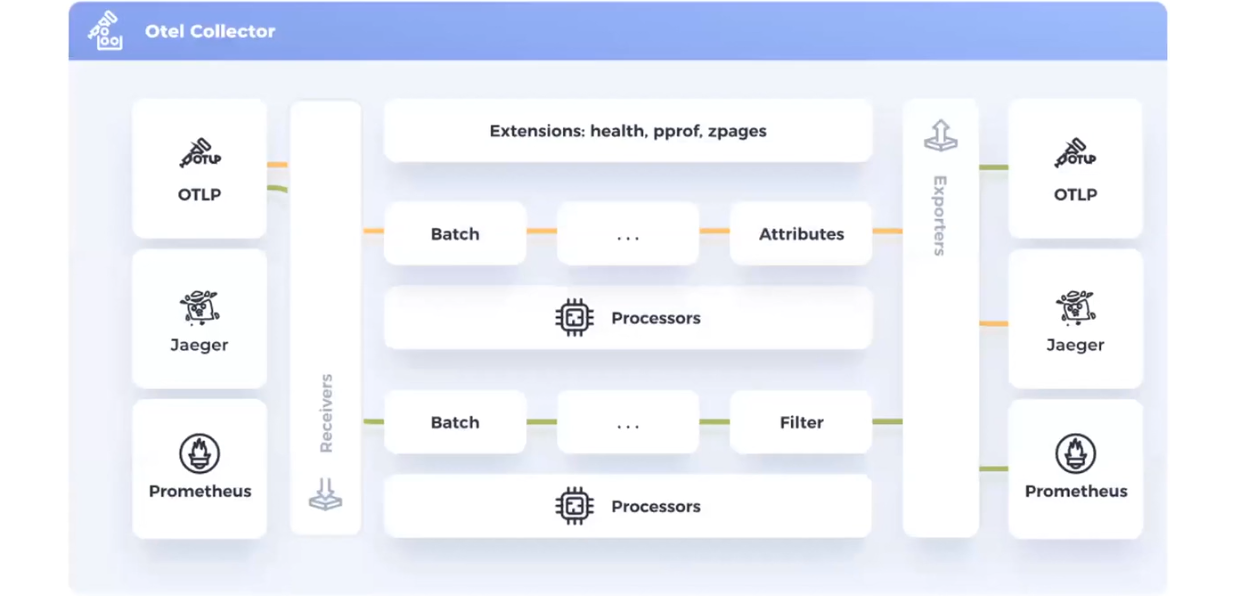
Колектор складається з чотирьох компонентів:
На цій схемі маємо два типи даних — метрики та логи (позначені різними кольорами). Логи йдуть через свій процесор до Jaeger. Метрики прямують через інший процесор, мають свій фільтр і відправляються до двох джерел даних: OTLP і Prometheus. Це надає гнучкі можливості аналізу даних. Адже різний софт має різні способи демонстрації телеметрії.
Цікавий момент: дані можна приймати з OpenTelemetry і надсилати їх туди ж. Тобто в певних випадках однакові дані ви можете надсилати в один і той самий колектор.
Існує багато способів, як побудувати систему збору телеметрії. Одна з найпростіших схем зображена на ілюстрації нижче. Тут є один .NET-сервіс, який надсилає OpenTelemetry відразу до New Relic:
За необхідності схему можна доповнити агентом. Він може виступати як хост-сервіс чи бекграунд-процес всередині сервісу, збирати дані та надсилати їх до New Relic:
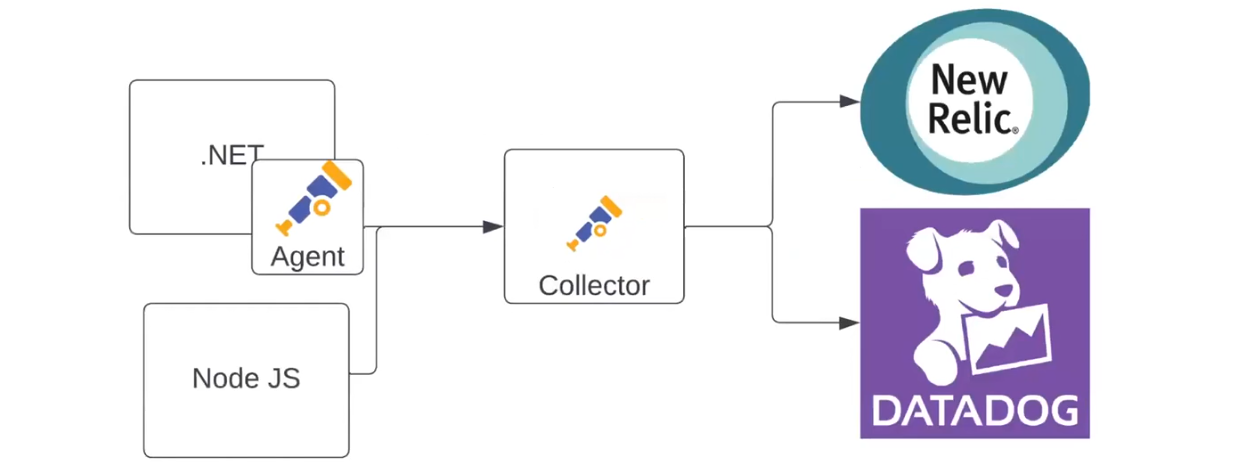
Йдемо далі — додаємо у схему ще один застосунок (наприклад, на Node JS). Він надсилатиме дані напряму до колектора. А перший робитиме це через власного агента за допомогою OTLP. Колектор надсилатиме дані вже до двох систем. Наприклад, метрики йтимуть до New Relic, а логи — до Datadog:
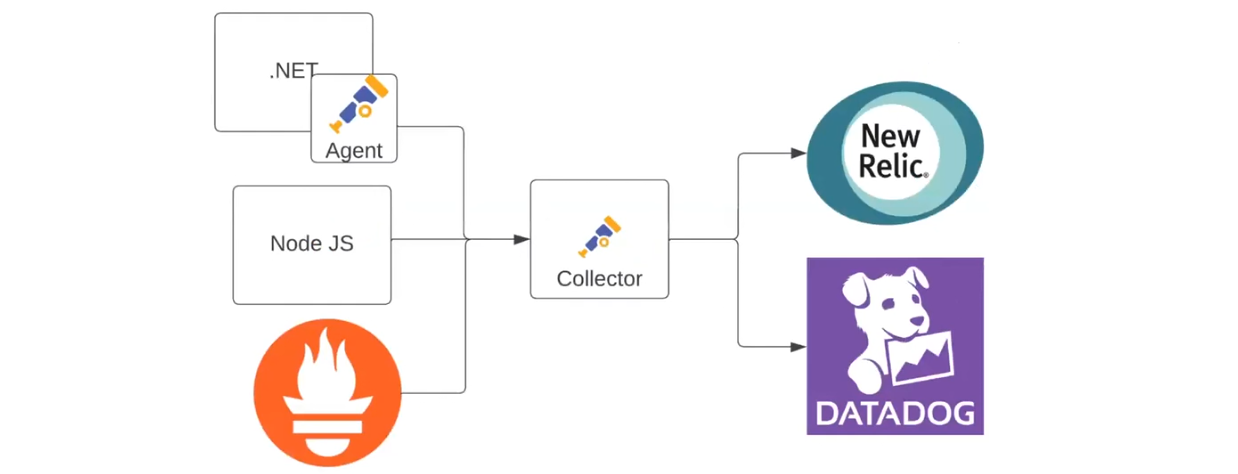
Сюди ще можна додати Prometheus як джерело даних. Наприклад, коли в команді з’явилася людина, яка полюбляє цей інструмент і хоче використовувати його. Тут дані все одно збиратимуться в New Relic та Datadog:
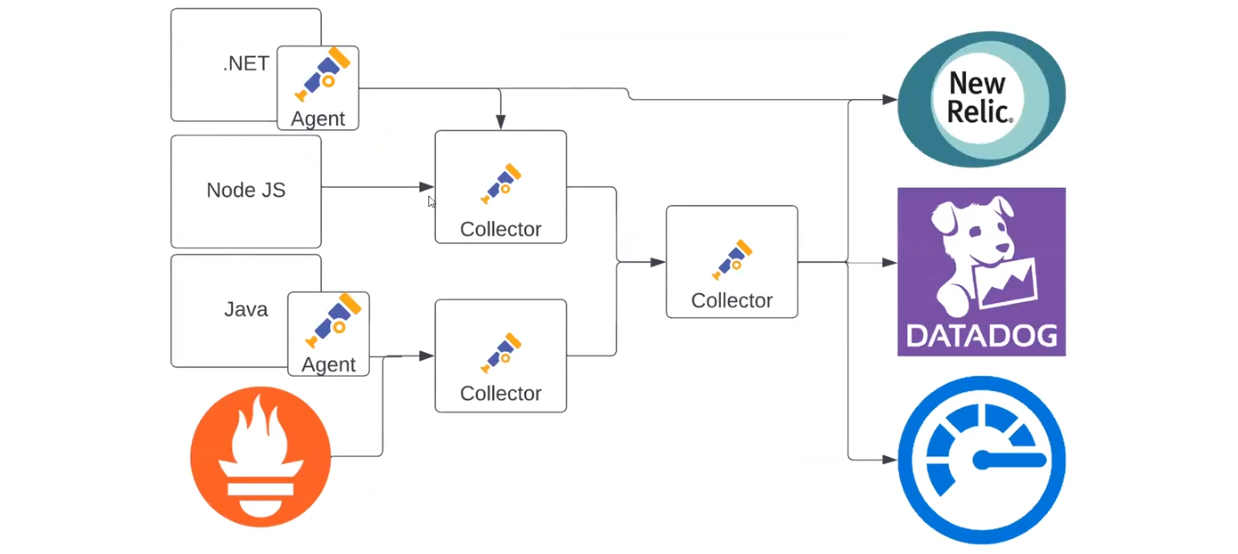
Систему телеметрії можна ускладнювати нескінченно, адаптуючи її під свій проєкт. Ось ще один приклад:
Тут є декілька колекторів, кожен з яких збирає дані по-своєму. Агент у .NET-застосунку відправляє дані до New Relic і до колектора. При цьому один колектор може відправляти інформацію до іншого, тому що OTLP надсилається до іншого джерела даних. Воно може робити з ними що завгодно. В результаті перший колектор фільтрує потрібні дані та передає наступному. Останній — розподіляє логи, метрики та трейси між New Relic, Datadog та Azure Monitor. Завдяки цьому механізму аналізувати телеметрію можна так, як зручно саме вам.
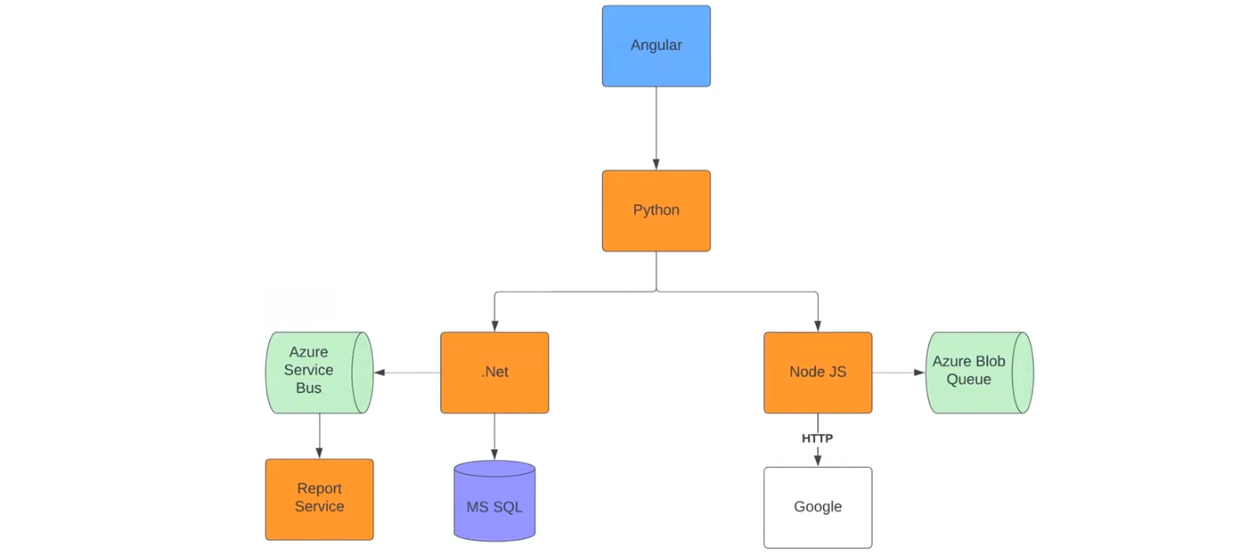
Передусім — це гнучкість. Розглянемо дану властивість на практиці. Для цього тестування я зробив проєкт за наведеною схемою:
Все починається з Angular-застосунку, який відправляє HTTP-реквести до Python-застосунку. Той зі свого боку надсилає реквести до застосунків на .NET та Node JS. Вони працюють за своїми сценаріями. Застосунок на .NET відправляє до Azure Service Bus реквести та хендлить їх у Report Service.
Потім надсилає метрики про те, скільки реквестів він обробив. Додатково .NET відправляє реквести до MS SQL. Реквести Node JS йдуть до Azure Blob Queue та Google. Тобто система емулює якусь роботу. В усіх застосунках використовуються автоматичні системи відправки трейсів до колектору.
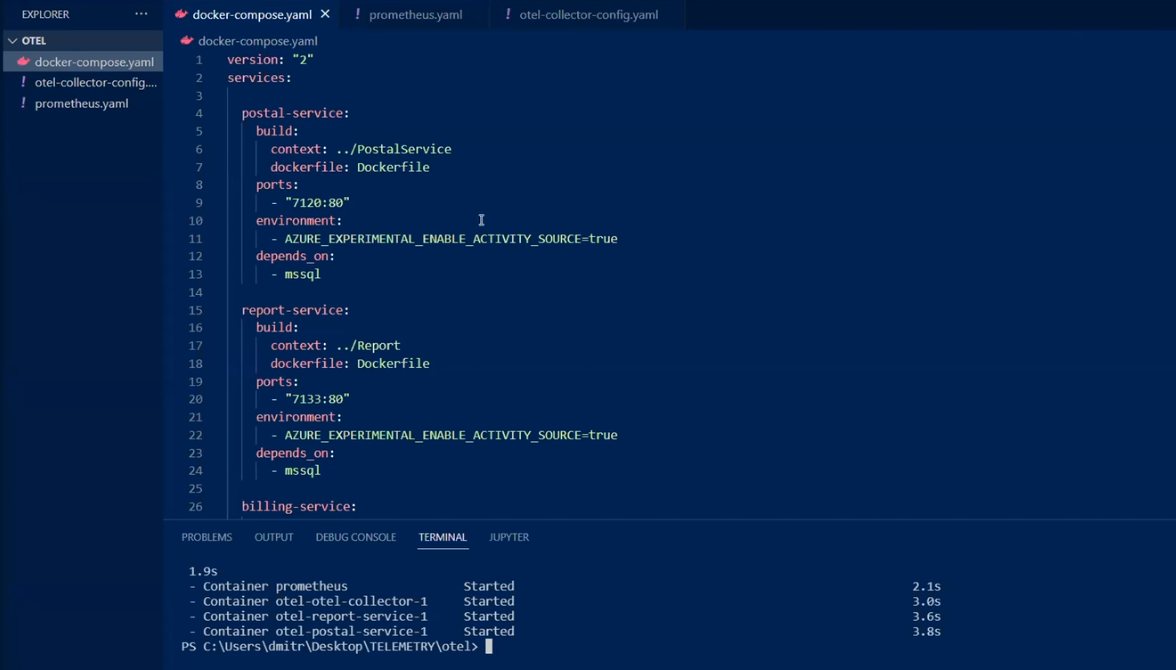
Почнемо з розбору docker-compose файлу.
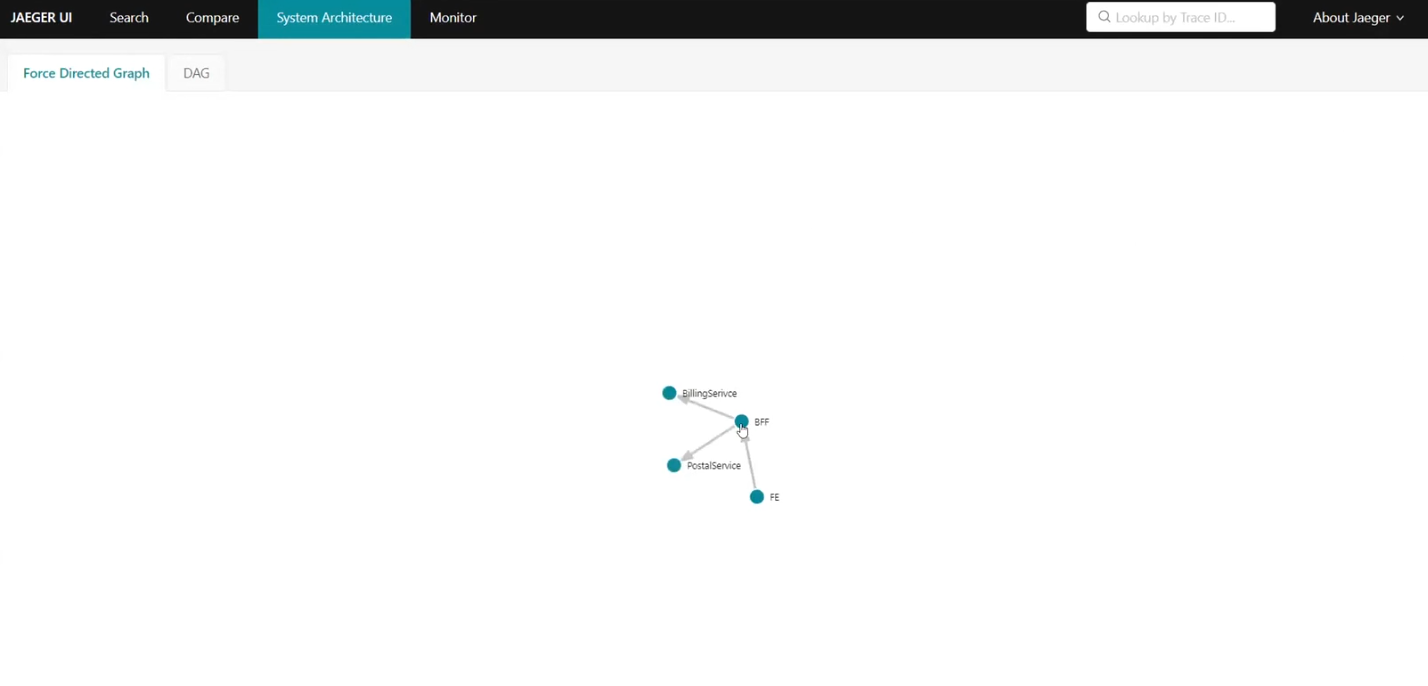
Тут зібрано сетап декількох сервісів BFF. Серед закоменчених — Jaeger, який допомагає дивитися трейси.
Передбачено ще один софт для перегляду трейсів — це Zipkin.
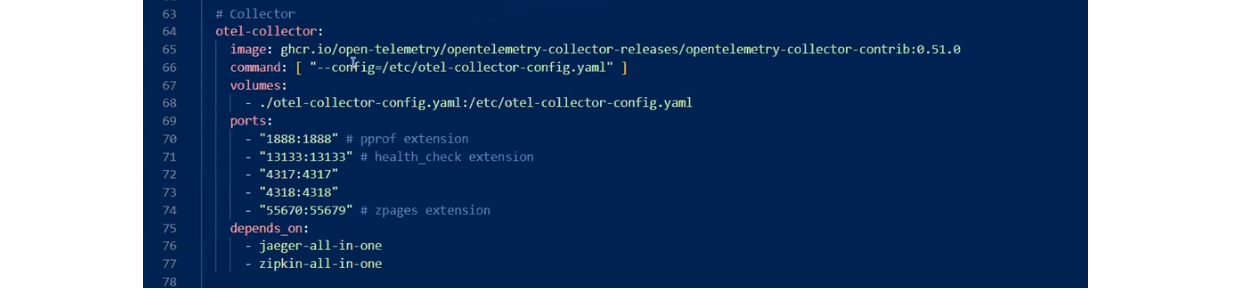
Також є MS SQL та власне колектор. В останньому вказано config-файл і багато портів, на які можна щось відправляти.
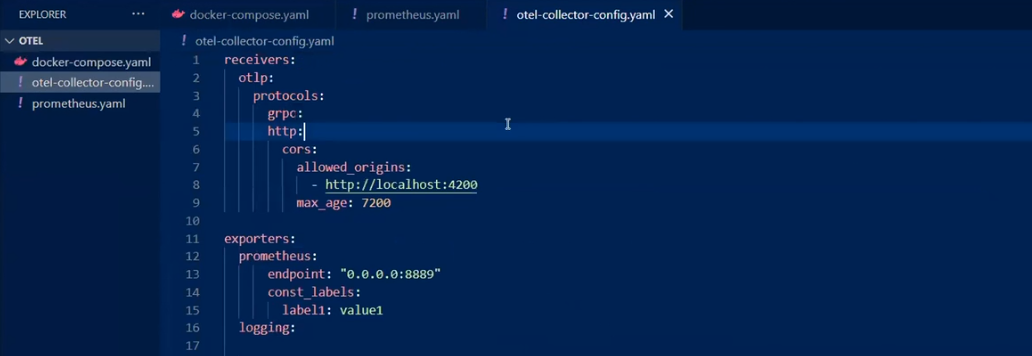
Сonfig-файл містить набір головних топіків: recievers, exporters, processors, extensions. Завершує все service. Він виступає як конструктор усього цього.
Ресівер один. Це otlp, тобто саме Open Telemetry Protocol. Хоча можна підключати й інші ресівери (наприклад, Prometheus). Ресівер можна конфігурувати. Припустимо, сетапити allowed_origins, як у моєму прикладі.
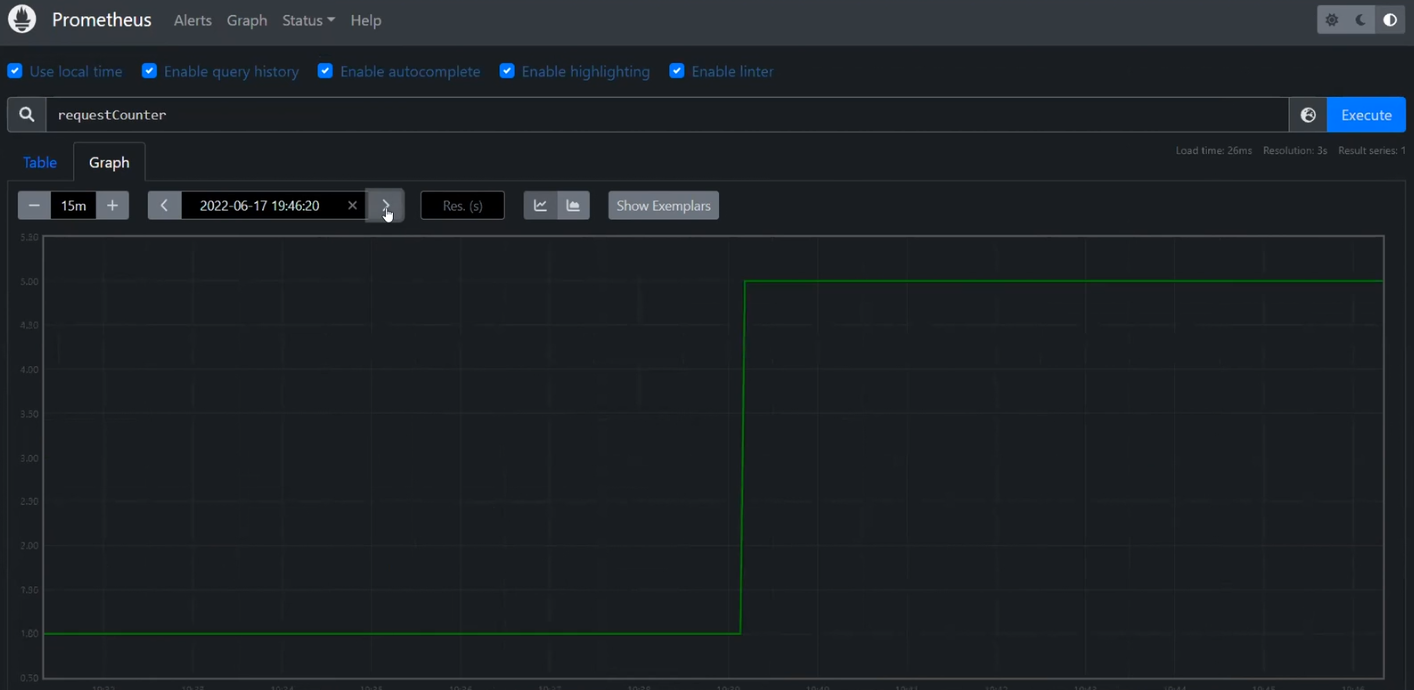
Наступний елемент — експортери. З ними можна відправляти метрики до Prometheus.
health_check. Він є ендпойнтом, який перевірятиме активність колектору.
pipelines, traces, metrics. З ними зрозуміло, який тип даних звідки береться, чим він обробляється, куди надсилається. В цьому прикладі трейси з ресіверу відправляються для логування на два бекенди, а для метрик використовується Prometheus.
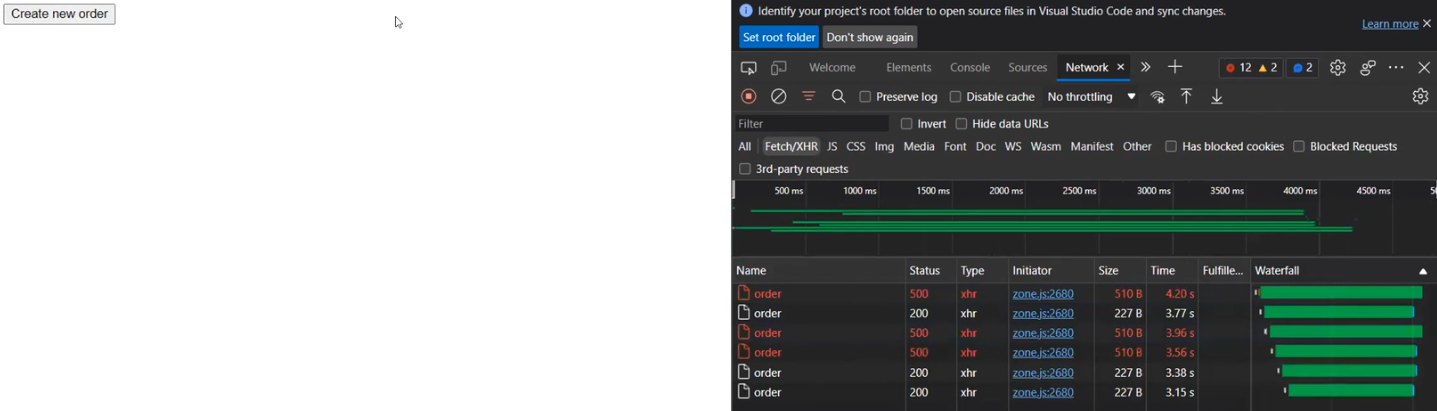
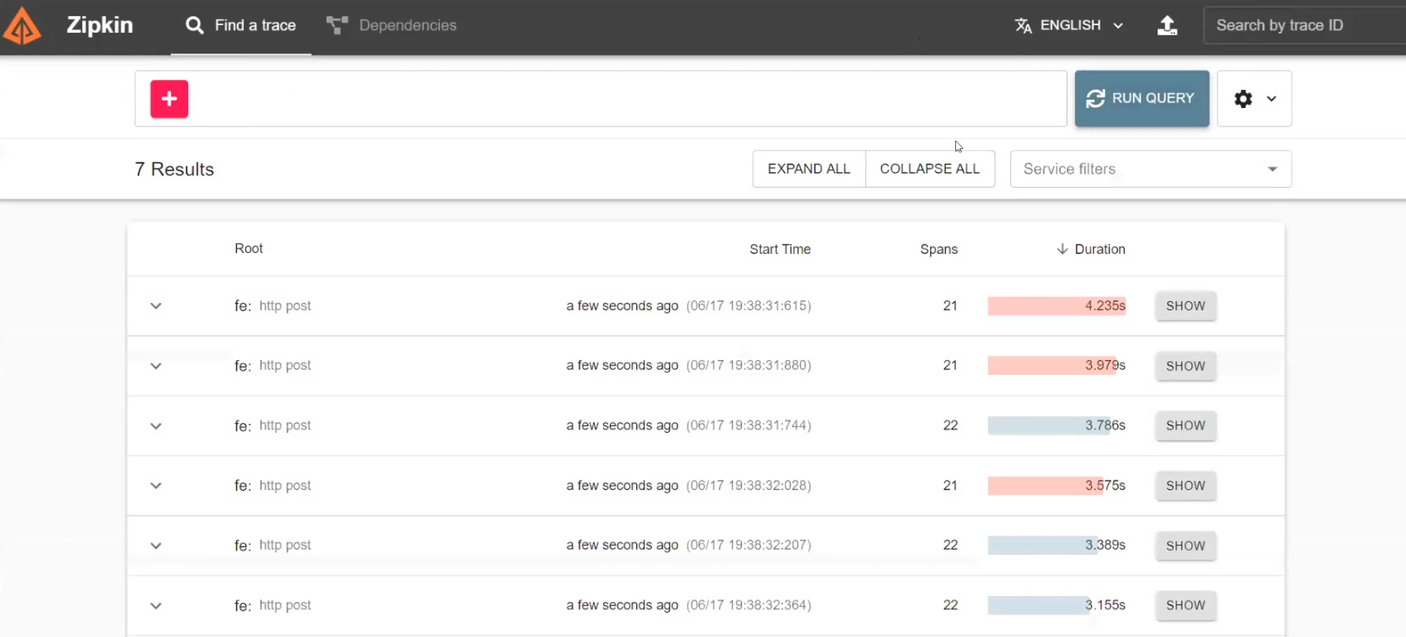
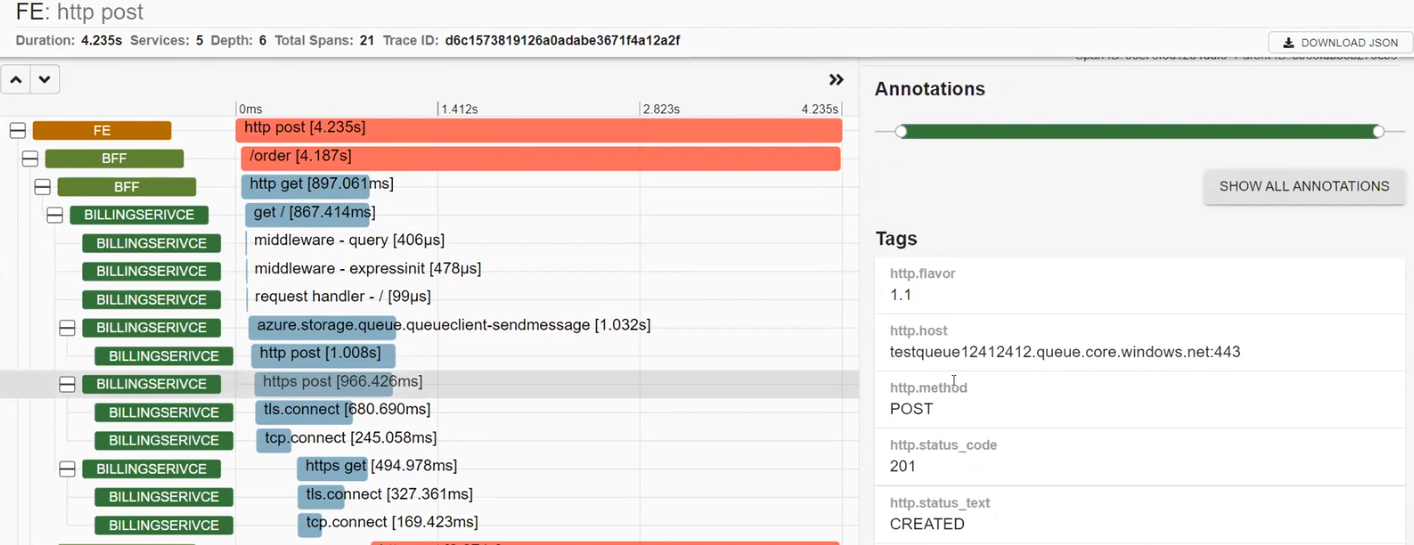
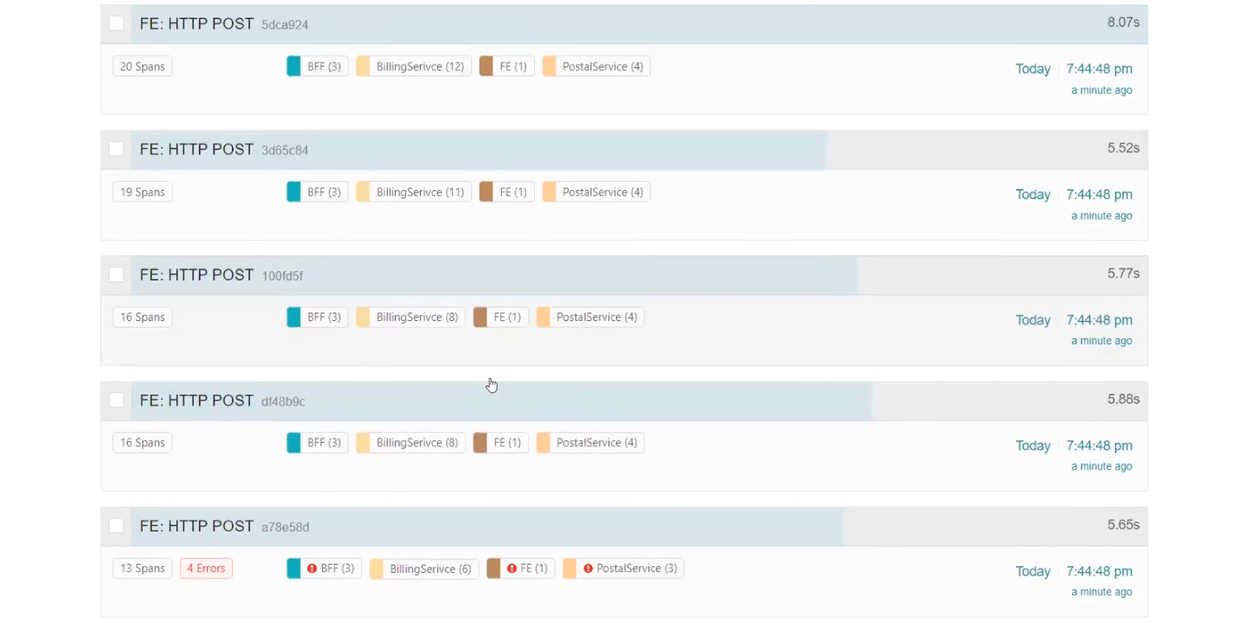
Розберемо, як це працює в реальності. Фронтенд надсилає реквести до бекенду, а бекенд використовує BFF для відправки реквестів. Створюємо кол і бачимо результати. Серед них, наприклад, є деякі реквести зі статусом 500.
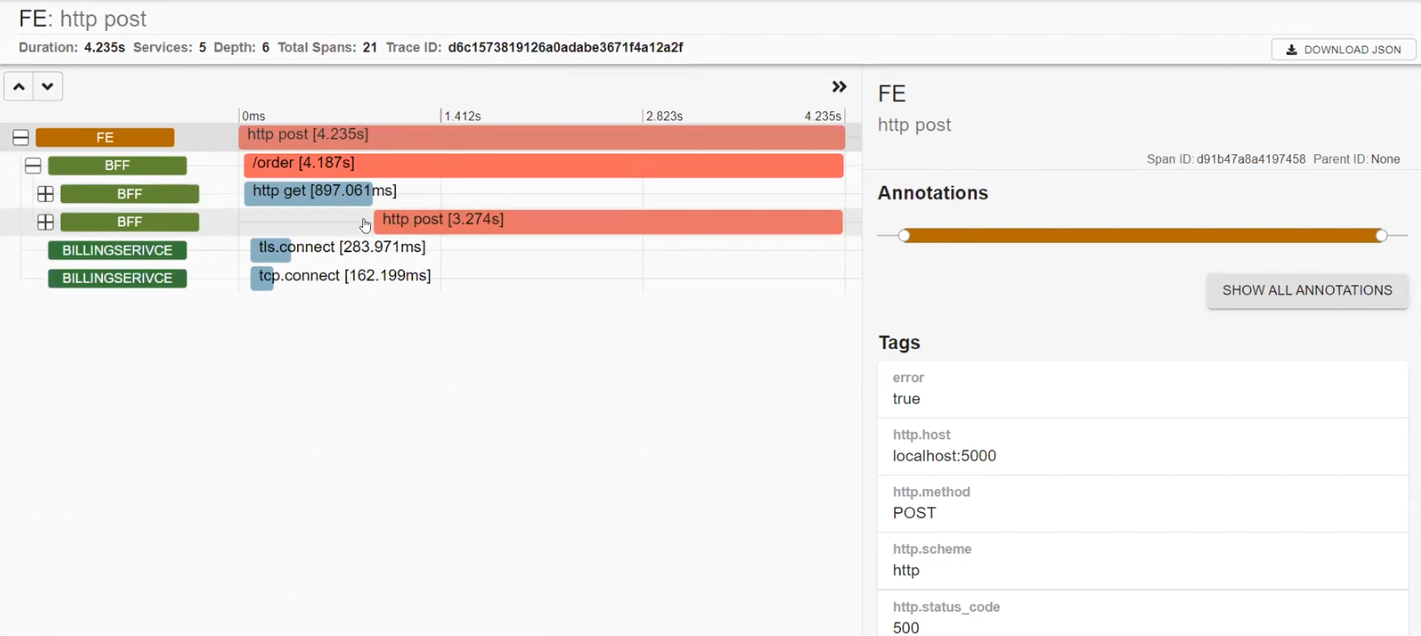
BFF викликав BILLINGSERVICE. У ньому працюють middleware, надсилається реквест до Azure та є http.post, який відправлявся до Azure. В результаті отримано статус CREATED. Далі система сетапила і відправляла реквест до Google.
POSTALSERVICE, в якому впав один реквест. Подивимося на нього уважніше і побачимо опис помилки: ServiceBusSender has already been closed… Тому наступного разу треба бути обережним з ServiceBusSender. Також тут можна побачити відправку декількох запитів на MS SQL.
А ще згадаймо про health_check. Він покаже, чи взагалі працює наш колектор.
Тож переваги використання OpenTelemetry Protocol очевидні. Це гнучка система для збору, обробки та відправки телеметрії. Особливо зручно у поєднанні з Docker, який я використовував при створенні цього демо.
Проте завжди пам’ятайте про обмеження OTLP. У випадку з трейсами все досить добре. А от доцільність використання цього протоколу для метрик і логів залежить від готовності бібліотек та SDK конкретної системи.
Ідея «соціальних фінансів» у криптосвіті витає вже кілька років, але все ніяк не може набути…
За останні десять років криптоіндустрія пройшла шлях від експериментальної ніші до одного з ключових сегментів…
Щосекундно збільшується обсяг інформації в мережі. Бізнес збирає дорогоцінні байти даних, структурує їх, аналізує і…
Штучний інтелект (ШІ) вже не просто модне слово, а рушійна сила, що змінює саму суть…
Алгоритм консенсусу – це серце будь-якого блокчейна. Саме він визначає, хто і як записує нові…
Зайшов на сторінку, а там — спінери, skeleton і порожнеча? Це не баг, це —…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}