Зміст
Сьогодні ми розглянемо важливий інструмент взаємодії з базами даних — Hibernate. Ви дізнаєтеся, що це за бібліотека, в яких випадках та як нею користуватися, а також вивчите як реалізована робота з БД в Java.
Але перед тим, як перейти до розмови про Hibernate, потрібно сказати пару слів про те, що означає ORM, JDBC і про деякі принципи роботи з БД.
Коли Java-програма встановлює зв’язок з базою даних, вона не відправляє запити до таблиць безпосередньо, а використовує для цього програмний інтерфейс JDBC (Java Database Connectivity). Підключення до БД та подальша взаємодія з нею відбувається через спеціальні драйвери. Замість того, щоб створювати окремий набір методів і процедур, які працюватимуть із конкретною базою даних (як наприклад, це зроблено в PHP — де є окремі набори процедур для MySQL, Postgres та інших БД), в Java був придуманий єдиний інтерфейс.
Він дозволяє будь-якій Java-програмі мати справу з різними реляційними базами через абсолютно однакові методи. Щоб у кожному випадку робота йшла з єдиними методами, слід задіяти JDBC-драйвери. Динамічно підвантажуючись по ходу виконання програми, такий драйвер автоматично ініціалізується та викликається, коли програма запитує URL-адресу, що включає протокол, за який відповідальний драйвер.
Код звичайного драйвера JDBC MySQL під платформу Linux має вигляд:
package javaapplication1;
import java.sql.*;
public class Main {
public static void main(String[] args) throws SQLException {
/**
* Цей код виконує завантаження драйвера DB.
*/ //Class.forName("com.mysql.jdbc.Driver");
Connection conn = null;
try {
conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/db_name",
"user", "password");
if (conn == null) {
System.out.println("Відсутній зв'язок із БД!");
System.exit(0);
}
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
while (rs.next()) {
System.out.println(rs.getRow() + ". " + rs.getString("firstname")
+ "\t" + rs.getString("lastname"));
}
stmt.close();
}
catch (SQLException e) {
e.printStackTrace();
} finally{
if (conn != null){
conn.close();
}
}
}
} При переключенні з однієї БД на іншу робота Java-програми ніяк не змінюється, що вигідно відрізняє цю реалізацію від, скажімо, мови PHP, де перехід з однієї БД на іншу вимагає від розробників переписування цілого шару роботи з базою даних (з використанням інших методів).
Обов’язок щодо створення JDBC-драйвера лежить на вендорі бази даних. До будь-якої БД такий драйвер вже існує та підтримується розробником, його легко можна знайти в інтернеті.
Набір операцій JDBC стандартний та дуже простий:
statement;Result set;select.Існує ряд фундаментальних проблем, пов’язаних із роботою мови Java з реляційними базами даних. Мова Java використовує парадигму ООП, тому ми весь час маємо справу з об’єктами. У той самий час реляційні бази даних оперують таблицями.
Об’єкти в Java та таблиці в БД — це різні сутності, які складно між собою зіставити. З іншого боку, для вирішення завдань нам завжди потрібно якимось чином перетворювати об’єкти на таблиці та навпаки. Завдання нетривіальне, вирішити яке складно — потрібно писати деяку логіку, використовуючи той же JDBC.
Переваги JDBC:
Недоліки JDBC:
У простих випадках застосовувати JDBC не складно (наприклад, був об’єкт «Користувач», і для того, щоб записати його до бази даних, ми з деякого рядка дістаємо id, ім’я тощо). Але якщо ми матимемо справу зі складним графом об’єктів, зберегти його в базу даних буде вже не так легко — доведеться писати довгий SQL-код, який потім буде дуже складно перевірити. Крім того, ми маємо справу в Java з класом based object oriented language, де є успадкування, а в таблицях його немає.
Якщо ви пишете серйозну програму, то будете працювати з кодом на величезну кількість рядків. Вся сучасна бекенд-розробка — це робота з великою кількістю інформації. Як наслідок — розробник має справу з постійними запитами до БД. Йому необхідно чи не в кожному рядку написати connect, отримати, витягти дані з бази, потім рядки та цифри потрібно розкласти по полях об’єктів. Серйозний enterprise–об’єкт може містити до десяти тисяч полів і, відповідно, у вас буде десять тисяч рядків. Ситуація ускладнюється тим, що такі об’єкти постійно змінюються — тому доводиться вирішувати безліч проблем.
Об’єктна модель даних та модель даних у реляційних таблицях не дуже збігаються. Є певна логіка порівняння об’єктів, і ніхто не гарантує, що ця логіка збігається і в базі даних, і у застосунку. Це може призвести до великої кількості помилок.
Наприклад, ви створили нового користувача, помістили його до бази даних, а потім раптом виявилося, що у БД він вважається іншим користувачем через те, що там критерії порівняння інші.
Ми повинні стежити, щоб у об’єктної моделі Java та тій, що зберігається у основі, сутності збігалися, щоб була та сама логіка порівняння.
У об’єктній моделі даних Java також є деякі додаткові можливості — наприклад, різні рівні доступу до різних полів. Деякі поля ми б не хотіли мати в БД, деякі ми не хотіли б витягувати або записувати.
Щоб не писати код зайвий раз і думати про JDBC, було взято концепцію ORM.
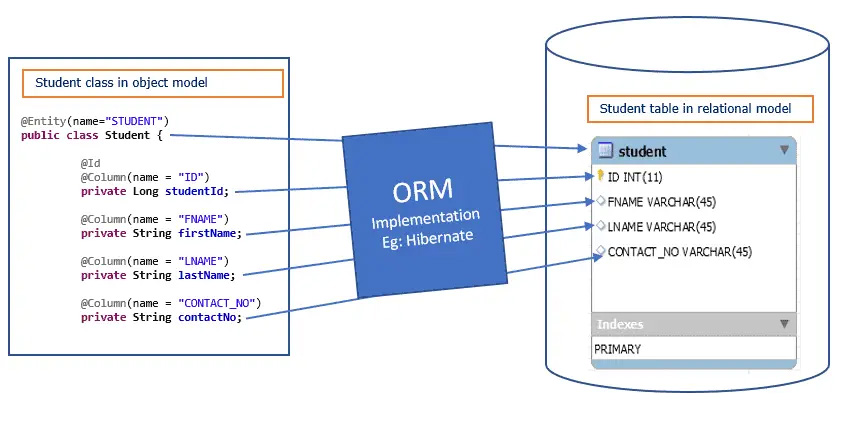
Object-Relational Mapping — це механізм, який дозволяє відображати дані з реляційних баз даних у вигляді об’єктів. ORM-системи полегшують роботу з базами даних, зменшуючи необхідність керуватися SQL-командами.
У Java присутня специфікація JPA (Java Persistence API). Вона визначає способи керування даними та містить інструменти:
insert, select та ін.), стандартних операцій (створення, читання, оновлення та видалення).Щоб реалізувати JPA, нам знадобиться так звані JPA-провайдери — бібліотеки, які його реалізують.
Таких провайдерів існує багато для різних мов програмування:
Більше половини імплементацій JPA виконано на фреймворку Hibernate з відкритим кодом, чим пояснюється популярність цієї бібліотеки.
Hibernate прямо в програмному коді за допомогою додаткового файлу конфігурації або анотацій на полях визначає, яке поле співвідноситься з яким полем в базі даних.
Іншими словами: проводиться об’єктно-реляційний меппінг (ORM). Завдяки Hibernate (який використовує програмний інтерфейс JDBC) програмісти не замислюються, як поля бази даних потрапляють у поля об’єктів.
Для роботи Hibernate використовує HQL — еквівалент мови SQL, тільки з урахуванням Java-класів. Фреймворк може застосовуватися у будь-якому типі додатків — desktop/web, Spring тощо. Сьогодні Hibernate портований до інших мов, наприклад, для C# (.NET) використовується Nhibernate.
Підіб’ємо підсумки. Hibernate застосовується у Java-розробці, коли виникає необхідність перенести з бази даних інформацію в код і якось її обробити. Цей фреймворк допомагає оптимізувати код низького рівня, прискоривши його написання і зробивши його більш компактним і зручним для розробників.
Схема роботи нашої програми виглядає приблизно таким чином:
Програма спілкується з базою даних через Hibernate через JDBC-конектор, використовуючи конфігурацію conf. У цих параметрах конфігурації вказано, як Hibernate повинен передавати дані.
Подання Java-класів з таблицями БД реалізується у вигляді XML-файлів із конфігураціями або через Java-анотації.
Коли даних багато, зв’язки між сутностями розробникам створюють головний біль. Hibernate має стандартний набір зв’язків, які можуть їм знадобитися:
Перед тим, як розпочати роботу з Hibernate, вам потрібно буде вивчити:
Зазвичай для створення будь-якої програми Hibernate необхідно виконати такі дії:
1. Створити проєкт та підключити залежності.
2. Додати параметри роботи Hibernate.
3. Виконати представлення класів для зв’язування таблиць БД з кодом.
4. Створити SQL-запити для бізнес-процесів (select, update, delete тощо).
5. Опрацювати результати запитів.
6. Подати результати у потрібному форматі у зовнішньому графічному інтерфейсі (web, Android, десктопний застосунок тощо).
Один із способів оптимізації та прискорення роботи програми — кешування.
У Hibernate використовується три рівні кешів:
persistence context. Припустимо, ви хочете вивантажити сутність із БД. Вона вивантажується один раз і потрапляє до persistence context. Ви відразу хочете вивантажити ще раз, і Hibernate вже не звернеться до БД, а візьме з persistence context. Працюючи з цим типом кешування нерідко виникають сайд-ефекти. Наприклад, він добре працює через EntityManager. Але буває так, що якщо ви змінюєте сутності поза EntityManager, хтось в іншій транзакції звертається до БД та змінює сутність. У першій транзакції вона вивантажена і якщо ви захочете перевірити, чи вона підходить під ваші параметри, сутність вже буде іншою. Але ви про це не будете знати, тому що у вас буде задіяний кеш першого рівня.Hibernate, безумовно, зручний. Найпопулярніші IDE (середовища розробки) підтримують цей фреймворк через плагіни. Але хоча бібліотека і допомагає нам прибрати «спагетті» з коду, спростивши його, вона все ж таки має ряд недоліків:
У Hibernate часто зустрічаються конфігурації за умовчанням — імена таблиць, стовпців тощо. Крім того, для деяких параметрів фреймворк сам «здогадується» про необхідне значення.
Наприклад, ви можете забути зробити інструкцію і Hibernate може сам спробувати зв’язати сутності через додаткову таблицю. При цьому він зробить припущення, як саме має називатись ця проміжна таблиця. Звичайно, це ще не факт, що вгадає правильно 🙂
Оскільки Hibernate має не одну бібліотеку, а кілька, слід їх всіх підключити. Наш проєкт будемо використовувати зі збирачем Maven, який відповідатиме за завантаження необхідних нам бібліотек.
pom.xml, що містить інформацію про залежності та інші опції. Усередині папки java будемо писати java-класи, у папці resources будуть всі файли конфігурації Hibernate.
Файл pom.XML виглядає так:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.app.HibernateTest</groupId> <artifactId>QuickStart</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>19</maven.compiler.source> <maven.compiler.target>19</maven.compiler.target> </properties> </project>
У розділі залежностей (dependency) ми маємо вказати, що ми будемо працювати з Hibernate:
pom.xml:
<!-- https://mvnrepository.com/artifact/org.hibernate/hibernate-core --> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> <version>6.1.6.Final</version> <type>pom</type> </dependency>
Далі по пошуку в репозиторії шукаємо відповідні залежності для конектора БД і вставляємо їх також:
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.32</version> </dependency>
Принципового значення, яку версію брати, немає, але ви повинні розуміти, що якщо щось не працює або працює не так, як хотілося, можливо, варто спробувати іншу. На жаль, часто виникають помилки.
Створимо клас Student, який містить поля, які потрібно промапити. Додамо публічний конструктор і перевизначимо метод:
package com.app.pojo;
public class Student {
private int id;
private String name;
private int age;
public Student(){}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
} Перед початком роботи з базою пропишіть параметри у файлі hibernate.cfg каталогу resources. Є ще альтернативний варіант із xml-налаштуваннями — через файл persistence.xml. Він застосовується для будь-якої реалізації JPA (у тому числі і Hibernate), але він, зрозуміло, обмежений специфікацією JPA.
Створимо hibernate.cfg:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <!-- Version 8 MySQL hiberante-cfg.xml example for Hibernate 5 --> <hibernate-configuration> <session-factory> <property name="connection.driver_class">com.mysql.cj.jdbc.Driver</property> <!-- property name="connection.driver_class">com.mysql.jdbc.Driver</property → //Вказуємо, де шукати драйвер; <property name="connection.url">jdbc:mysql://localhost:3306/mydb</property> //Шлях, яким буде йти запит при звертанні до бази данних (для нашого прикладу - testdatabase на порту 3306, назва БД - mydb) <property name="dialect">org.hibernate.dialect.MySQL8Dialect</property> <property name="connection.username">root</property> //Користувач <property name="connection.password">root</property> //Пароль <property name="connection.pool_size">3</property> <!--property name="dialect">org.hibernate.dialect.MySQLDialect</property→ //Діалект для БД, до якої буде йти підключення; <property name="current_session_context_class">thread</property> <property name="show_sql">true</property>//відображення SQL-запитів; <property name="format_sql">true</property> <property name="hbm2ddl.auto">update</property> //Поле, необхідне для того, аби дати дозвіл Hibernate на обновлення даних у БД. Якщо дані будуть відсутні, він їх згенерує. <!-- mapping class="com.mcnz.jpa.examples.Player" / --> </session-factory> </hibernate-configuration>
Усередині конфігураційного файлу створюється секція session-factory — фреймворк відкриває сесію, протягом якої робить запити. Як тільки сесія буде закінчена, він її закриватиме. Порядок властивостей (property) у конфігураційному файлі не має значення.
Для отримання сесії можна використовувати два головні об’єкти — SessionFactory (JPA — EntityManagerFactory) та Session (JPA — EntityManager). SessionFactory створюється лише один раз при запуску програми, він налаштовує, працює з сесіями. Під час створення SessionFactory зчитуються параметри hibernate.cfg.xml.
Створимо ще один клас — наш Java-додаток App. Id для студента створювати не будемо, цей ідентифікатор автоматично створюватиметься у БД одночасно з появою нового запису.
Зверніть увагу: унікальний ключ має бути завжди, якщо ми його створюємо, то у БД він створюватися не повинен, інакше у базі даних будуть помилки.
Ми хочемо передати дані нашого студента до таблиці. Відповідно, бажано було б написати щось просте, наприклад save(Serge):
package com.app;
import com.app.pojo.Student
import org.hibernate.cfg.Configuration;
public class App {
public static void main(String[] args) {
Student Serge = new Student();
Serge.setName("Serge");
Serge.setAge(10);
//Serge.setId();
Configuration con = new Configuration().configure;
con.addAnnotatedClass (Student.class);
StandardServiceRegistryBuilder sBilder = new StandardServiceRegistryBuilder()
.applySettings(con.getProperties());
SessionFactory sf = con.buildSessionFactory(sBilder.build());
}
}
} Якщо це необхідно, у конфігураційному файлі ми можемо написати, скільки потоків фабрика сесій може генерувати для роботи з клієнтами. Після того, як фабрику сесій прописано, можемо переходити до CRUD.
Почнемо з команди Create:
public class App {
public static void main(String[] args) {
Student Serge = new Student();
Serge.setName("Serge");
Serge.setAge(10);
//Serge.setId();
Configuration con = new Configuration().configure;
con.addAnnotatedClass (Student.class);
StandardServiceRegistryBuilder sBilder = new StandardServiceRegistryBuilder()
.applySettings(con.getProperties());
SessionFactory sf = con.buildSessionFactory(sBilder.build());
//create
Session sessionCreate = sf.openSession();
Transaction trCreate = sessionCreate.beginTransaction;//Початок транзакції
sessionCreate.save(Serge);
trCreate.commit();
sessionCreate.close();//Завершення транзакції
}
} Нагадаємо, транзакції дозволяють зберігати стан бази даних. Вони засвідчують, що зміни, зроблені в рамках транзакції, збережуться, або, навпаки, будуть відхилені.
Тому між створенням та комітом транзакції ми можемо зберігати відразу кілька об’єктів. Подивимося, як тепер працює наша програма. Візьмемо базу даних (принципового значення, що це буде за БД немає), підключимося до неї та подивимося на результат:
Serge. Значення id надано автоматично. При повторному додаванні користувача автоматично надається новий id. Крім основної таблиці Hibernate створив ще одну — hibernate_sequence. Це проміжна таблиця, в якій зберігається значення, що інкрементується value.
Транзакція пройшла, дані додані. Переходимо до команди Read та відкриваємо нову сесію:
//read Session sessionRead = sf.openSession(); Transaction trRead = sessionRead.beginTransaction(); Student student1 = sessionRead.find(Student.class, o:1); System.out.println(student1.toString()); trRead.commit(); sessionCreate.close();
Результат виведення в консоль:
Student{id=1, age=10, name=Serge}
Наступна команда Update:
//update
Session sessionUpdate = sf.openSession();
Transaction trUpdate = sessionUpdate.beginTransaction();
Student student2 = sessionUpdate.find(Student.class, o:2);
student2.setAge(20);
student2.setName("Alexander");
sessionUpdate.update(student2);
trUpdate.commit();
sessionUpdate.close(); Користувач у базі даних оновить своє ім’я та значення Age.
Остання транзакція — Delete:
//delete Session sessionDelete = sf.openSession(); Transaction trDelete = sessionDelete.beginTransaction(); sessionDelete.delete(student2); txDelete.commit(); sessionDelete.close();
Запис у таблиці буде знищено.
Hibernate — це зручний, потужний та ефективний ORM-фреймворк. Він простий у вивченні і суттєво заощаджує час розробки ПЗ, в якому йде звернення до баз даних. Використовуючи цей інструмент, програміст може зосередитись на основній логіці, скоротивши написання запитів до мінімуму.
Як бачите, використовувати Hibernate не складно. Головні труднощі, з якими вам доведеться зіткнутися, — правильне налаштування залежностей і конфігураційних файлів проєкту. Також важливо правильно користуватися інструментами для автоматизації складання проєктів: Maven, Gradle та іншими.
Посилання з конфігураціями в репозиторіях постійно змінюються, тому будьте уважні і якщо щось не працює — перевірте їх актуальність.
Стабільність роботи програми на Hibernate багато в чому залежить від версії Java і модулів (наприклад, Hibernate 6.1.3 з Java 17 викликає помилки, а та ж версія, але вже з Java 18 працює нормально).
Рой Лі, засновник вірусного стартапу Cluely, визнав, що збрехав журналістам про $7 мільйонів річного доходу.…
Популярний ШІ-редактор коду Cursor від компанії Anysphere робить наступний крок у розвитку агентного програмування. Новий…
У найближчі місяці в застосунку «Дія» з'явиться кілька нових функцій, в тому числі опція бронювання…
Соціальна мережа X анонсувала оновлення інструментів монетизації для авторів контенту. Основна зміна полягає в тому,…
Статистичний аналіз зарплат українських розробників, найнятих на Djinni за три місяці зими, демонструє суперечливі дані.…
Коли цього тижня стався збій в роботі інструментів вайб-кодування Claude, деяким розробникам програмного забезпечення довелося…
{kind=link}
{kind=link}
{kind=link}