Щоб моніторити роботу сучасних високорозподілених PHP-застосунків, знадобляться принципово нові підходи та технології. Це пов’язано із мікросервісною архітектурою програми, коли її різні частини реалізуються за допомогою незалежних модулів, розміщених на різних інстансах. І це не дає можливості відстежувати, як виконуються запити. А якщо код розміщується у хмарному середовищі, наприклад, в Azure або AWS – виявляти та локалізувати проблеми ще складніше з-за високого рівня динамічності інфраструктури.
Подолати всі ці труднощі здатні Observability – системи спостереження нового покоління. Існує чимало їх реалізацій, ми в FREEhost.UA використовуємо стек Grafana/Loki/Tempo. Для партнерського матеріалу розглянемо її більш детально.
Вихідні дані для Observability
Щоб зробити моніторинг високорозподіленого застосунку, знадобляться телеметричні дані про його роботу. Основними з них є логи, метрики та трейси.
Метрики
Метрики – це агреговані дані про роботу застосунку, котрі дають загальне уявлення про його стан. Їх перевага – чіткість та компактність зафіксованих даних. Цьому сприяє поділ на спеціальні типи: лічильник, зведення, гістограма тощо. У порівнянні із логами їх легко масштабувати та можна миттєво реагувати на проблему у коді із розсиланням алертів.
Логи
Логи є записами системних журналів, котрі надають корисну інформацію про застосунок на кількох рівнях – INFO, WARN, DEBUG та інших. Вони генеруються при виникненні будь-якої події під час роботи застосунку та містять наступні дані:
- системну інформацію про подію – час її настання, ID тощо;
- рівень логу;
- повідомлення;
- контекст.
Трейси
Трасування є одним з методів для профілювання та контролю роботи застосунку. Трейси – результат цього процесу, що дозволяє:
- зафіксувати послідовність виконання команд та модулів/мікросервісів на шляху виконання запиту;
- визначити затримку запиту при кожному виклику або пересиланні між двома сервісами.
Трейс запиту можна представити у вигляді дерева, в корні якого знаходиться батьківський трейс, а далі йдуть гілки – дочірні спани, кожен з яких реалізує певну функціональність.
Щоб система трасування працювала, обов’язковою умовою є наявність унікального TraceID для кожного запиту. Він генерується в точці входу та запам’ятовується у його заголовку. Після цього розповсюджується по шляху «руху» запиту через всі мікросервіси, котрі залучені у його виконанні (див. Малюнок 1). Це дозволяє відстежувати поведінку та продуктивність окремого запиту.
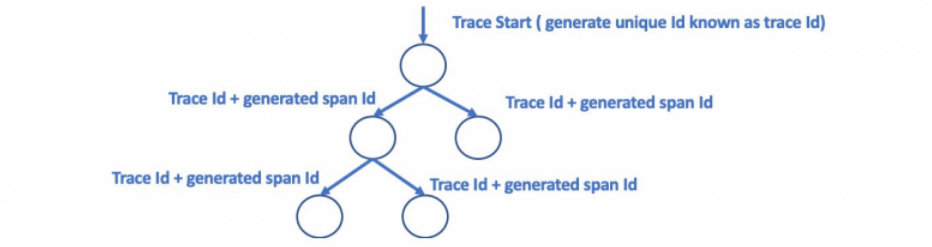
Малюнок 1. Шлях руху запиту із передачею по ланцюгу спанів його TraceID.
Кореляція логів та трейсів
Збільшити можливості аналізу та контролю високорозподілених систем можна за допомогою співставлення логів та трейсів для визначеного запиту через TraceID. Це, зокрема, дозволяє:
- пропускати через застосунок «еталонні» запити для усунення проблем;
- напряму співставляти метрики із логами;
- автоматично збирати системні логи для визначеного запиту;
- візуалізувати результати.
Така кореляція реалізована не для всіх Observability-систем, про що розповідаємо нижче.
Алерти
Алерти дозволяють автоматизувати процес виявлення негараздів у коді. Якщо значення параметра не відповідають допустимим нормам, то генеруватимуться повідомлення у месенджері або системі моніторингу. Такими параметрами є зібрані метрики, і саме вони «керують» процесом генерування алертів. Можна навіть сказати, що використання метрик без алертів на 50% марне.
Профайлінг
Профілювання коду застосунку дозволяє визначити, де знаходиться недосконала ділянка коду. Його застосування для високорозподілених систем має свої особливості. Щоб можна було отримати якісний результат, повинні бути застосовані профайлери із підтримкою трейсів та технології OpenTelemetry для їх передачі. Нижче розглянемо ряд реалізацій профайлерів та їх характеристики.
Підходи до реалізації Observability
У сучасній Observability-системі опція Distributed tracing має бути реалізована за допомогою механізму кореляції логів та трейсів. Лише в цьому випадку можна отримати ефективні результати моніторингу. Більшість існуючих реалізацій лише частково задовольняють цим вимогам. До них, зокрема, відносяться Zipkins, Cloud Sleuth та DataDog APM. Інші системи, хоча і підтримують технологію, але є занадто складними та ресурсоємними, як, наприклад, відома система моніторингу Jager.
Раніше у роботі ми розглянули систему, побудовану на базі стеку технологій Grafana/Loki/Tempo, який майже повністю задовольняє вказаним вимогам та може бути основою для побудови ефективної Observability-системи.
Grafana + Loki + Tempo
Grafana Tempo дозволяє реалізувати повний життєвий цикл Distributed tracing коштом підтримки наступних кейсів:
- Інструментація застосунку;
- Інтеграція із Loki;
- Бекенд трейсів (Tempo);
- Система керування метриками (Mimir);
- Засоби аналізу та візуалізації (Grafana).
Взаємодія елементів платформи представлена на Малюнку 2.
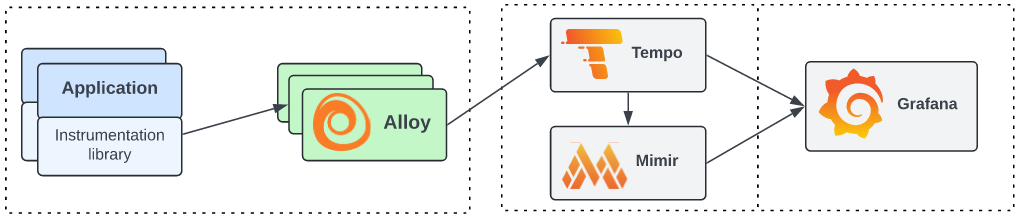
Малюнок 2. Взаємодія елементів Grafana Tempo.
Loki є централізованим сервісом для збору та зберігання логів. На Малюнку 3 наведена конфігурація стеку Loki разом з її компонентами.
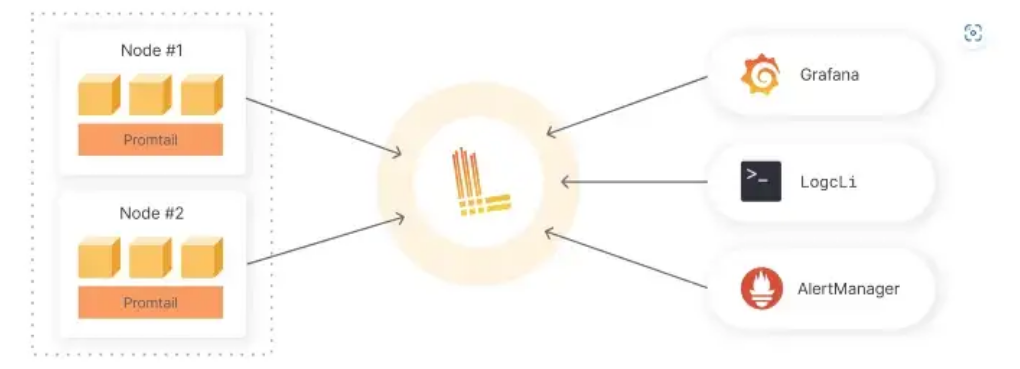
Малюнок 3. Конфігурація стеку Loki.
Замовити оренду хмарного, або фізичного сервера із конфігурацією Grafana + Loki можна на сайті хостер-провайдера FREEhost.UA.
У якості Alert-менеджера можна використовувати систему моніторингу Prometheus, котра водночас збирає та централізовано зберігає метрики, на основі котрих оповіщаються клієнти. Для довготривалого зберігання метрик доцільно під’єднати Grafana Mimir.
Реалізація профайлінгу
У Таблиці 1 наведено основні відомості про існуючі варіанти реалізації профайлінгу.
Таблиця 1. Порівняльна характеристика профайлерів.
| Інструмент | Вартість | FPM/CLI | UI та звіти | Особливості |
|---|---|---|---|---|
| php-excimer | – | + | + | Легкий, проста конфігурація, вибіркова профілізація slow-endpoints, інтеграція із CI/CD, Chrome Trace + web-UI |
| Xdebug | – | + | – | Для локального відлагодження |
| Tideways | + | + | + | Розширений моніторинг в продакшн, SLA і підтримка |
| Blackfire | + | + | + | Інтеграція із CI/CD, готові дашборди |
| Інші | – | – | – | Застарілі, не оновлюються (XHProf, PHP-Profiler та інш.) |
Вочевидь, найбільш прийнятний варіант – php-excimer.
Висновки
Отже, побудова Observability-систем повинна спиратися на метрики, логи, трейси та їх взаємну кореляцію з обов’язковим налаштуванням профайлінгу та алертингу.
Це був скорочений огляд інструментів Observability, розширений варіант статті можна переглянути на нашому сайті.
Це партнерський матеріал. Інформацію для цього матеріалу надав партнер.
Редакція відповідає за відповідність стилістики редакційним стандартам.
Замовити матеріал про вас у форматі PR-статті ви можете тут.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: