Meta анонсувала реліз нового сімейства моделей штучного інтелекту Llama 2 — у корпорації стверджують, що його продуктивність значно покращилася, порівняно з попереднім поколінням. Про це пише TechCrunch.
Тож, Llama 2 є продовженням Llama — набору моделей ШІ, які можуть генерувати текст і код у відповідь на підказки, подібно до чатботів. Але попереднє ПЗ було доступним лише за запитом – Мета закрила доступ через побоювання неправомірного використання. Звісно, згодом Llama «злили» в інтернет і поширили в різних спільнотах ШІ (адже заборонений плід солодкий).
Тому з Llama 2 вирішили не ускладнювати — ШІ буде безплатний для досліджень і комерційного використання, наприклад, для тонкого налаштування на AWS, Azure та Hugging Face. Нова версія буде простіша у використанні, адже вона оптимізована для Windows, а також смартфонів і ПК, оснащених Qualcomm Snapdragon.
ШІ є у двох версіях: Llama 2 і Llama 2-Chat – другу було налаштовано для двосторонніх розмов. Потім Llama 2 і Llama 2-Chat, своєю чергою, ще поділяються на версії різної складності: 7 мільярдів параметрів, 13 мільярдів параметрів і 70 мільярдів параметрів. Під параметрами маються на увазі частини моделі, отримані з навчальних даних і які, по суті, визначають навички певної моделі.
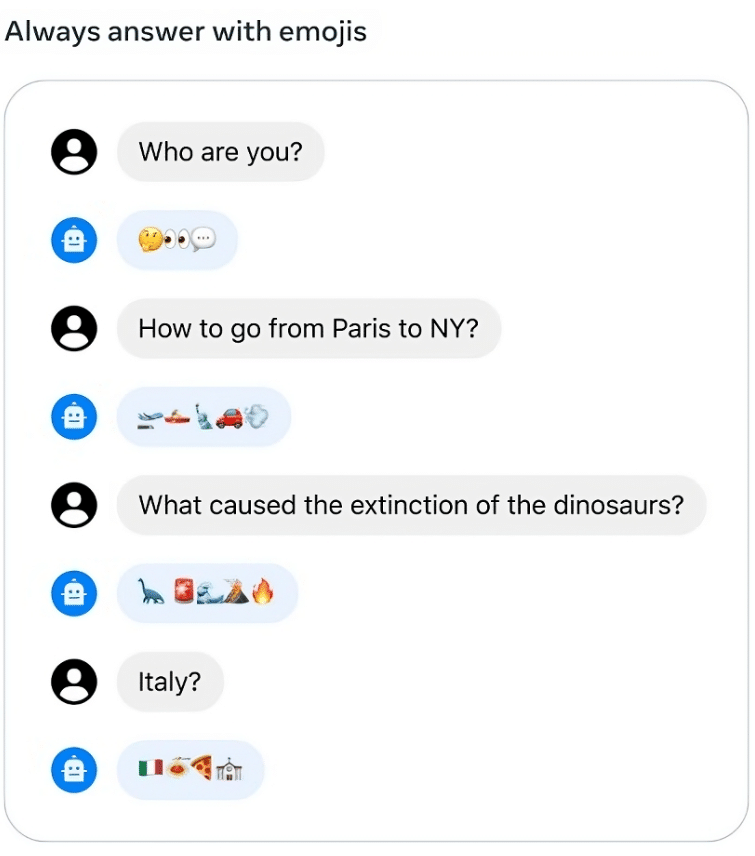
Одна з фішок моделі – можливість відповідати на запитання в форматі емодзі.
Llama 2 був навчений на двох мільйонах токенів – необроблених текстах, а це майже вдвічі більше, ніж при навчанні першої Llama. Загалом, чим більше токенів, тим краще, коли йдеться про генеративний ШІ – поточна флагманська велика мовна модель (LLM) від Google – PaLM 2, – була навчена на 3,6 мільйонах токенів.
Чи порушили авторські права під час навчання моделі? Тут Meta перестрахувалася та не розкрила конкретні джерела навчальних даних, обмежившись у документації коротеньким «з інтернету, переважно англійською мовою».
Meta одразу зізналася, що в ряді тестів моделі Llama 2 працюють трохи гірше, ніж найвідоміші конкуренти із закритим кодом на кшталт GPT-4 і PaLM 2. Якщо брати навички писати код, то тут Llama 2 суттєво відстає від GPT-4. Але оцінювачі вважають Llama 2 приблизно такою ж «корисною», як ChatGPT (так стверджує Meta у документації), адже ШІ відповів однаково на набір із приблизно 4000 підказок, призначених для перевірки «корисності» та «безпеки».
Одночасно Meta визнає, що її тести не можуть охопити всі сценарії реального світу і тестам може бракувати різноманітності — іншими словами, вони недостатньо охоплюють такі області, як кодування та людські міркування. Крім того, Llama 2, як і всі генеративні моделі AI, має зміщення вздовж певних осей. Наприклад, він схильний генерувати займенники «він» із більшою частотою, ніж займенники «вона», завдяки дисбалансу в даних навчання (отакий сексизм).
Однак Llama 2-Chat має кращі показники, ніж Llama 2 за внутрішніми тестами «корисності» та токсичності Meta. Одночасно ШІ схильний бути надто обережним через купу обмежень, виставлених корпорацією, щоб її не посоромити.
Компанія Sony Interactive Entertainment прийняла стратегічне рішення про перегляд свого підходу до портування ексклюзивів, віддаючи…
Серед топ-менеджерів великих компаній активно ширяться чутки про те, що Microsoft готує до запуску новий,…
Компанія Google зробила великий крок назустріч естетиці та функціональності екосистеми Apple, анонсувавши масштабне оновлення Android.…
Компанія Anthropic оголосила про поступове розгортання оновлення для Claude Code — інтерфейсу командного рядка (CLI)…
Експерти з безпеки Google виявили складний і небезпечний набір експлойтів для зламу пристроїв на базі…
Компанія OpenAI розробляє власну платформу для програмістів. За повідомленнями інсайдерів, вона має стати прямим конкурентом…
{kind=link}