«Звичайно, ви можете відмовитись»: GitHub ненав’язливо попереджає, що буде навчати LLM на вашому коді
Вже з 24 квітня 2026 року сервіс хостингу коду GitHub, який належить Microsoft, почне використовувати дані користувачів для навчання моделей штучного інтелекту. Це стосується «зокрема, вхідних та вихідних даних, фрагментів коду, коментарів, документації та іншого пов’язаного контексту».

Якщо ви ніколи не користувалися GitHub Copilot, нові правила вас не стосуються. Однак, якщо ви використовували автодоповнення коду в Visual Studio Code, ставили запитання Copilot на веб-сайті GitHub або використовували іншу пов’язану зі штучним інтелектом функцію, то ваші взаємодії та фрагменти коду можуть збиратись для навчання LLM.
Оновлена політика застосовується до клієнтів Copilot Free, Pro та Pro+. Користувачі Copilot Business та Copilot Enterprise звільнені від неї завдяки умовам їхніх контрактів. Студенти та викладачі, які мають доступ до Copilot, також не постраждають.
Ті, кого це стосується, мають можливість відмовитися відповідно до «встановленої галузевої практики» – тобто відповідно до норм США, на відміну від європейських норм, де зазвичай потрібна згода. Щоб відмовитися, користувачам GitHub слід відвідати сторінку /settings/copilot/features та прибрати опцію «Дозволити GitHub використовувати мої дані для навчання моделей ШІ» в розділі «Конфіденційність».
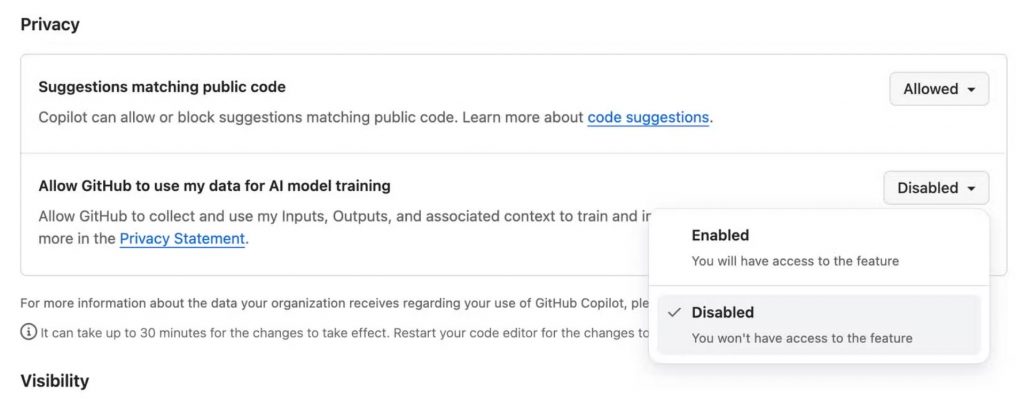
У блозі GitHub пояснює своє рішення тим, що початкові моделі штучного інтелекту для GitHub Copilot були «створені з використанням поєднання загальнодоступних даних та зразків коду, створених вручну», і компанія побачила позитивні покращення. Тепер GitHub сподівається, що сервіс стане ще кращим завдяки більшій кількості взаємодій з використанням нових навчальних даних.
Нагадаємо, найпопулярніший проект GitHub виявився шахрайством: це був софт, який допомагає «бачити крізь стіни».
Підписуйтесь на нас у соцмережах: Telegram | Facebook | LinkedIn








Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: