Приєднуйтесь до нас
LLM-модель
Anthropic випустила Claude Opus 4.7. Повний огляд можливостей нової моделі

Компанія Anthropic офіційно представила свою найпотужнішу на сьогодні LLM-модель — Claude Opus 4.7, яка стала помітним покращенням порівняно з Opus 4.6, особливо в сфері розробки програмного забезпечення.
Claude Opus 4.7 та новий дизайн-інструмент: Anthropic готує подвійний удар

Компанія Anthropic готується до масштабного розширення своєї екосистеми. Вже цього тижня Anthropic представить LLM Claude Opus 4.7 разом із новим ШІ-інструментом для розробки вебсайтів та презентацій, пише The Decoder.
«Банки почнуть зламувати першими»: міністр фінансів США Скотт Бессент терміново зібрав банкірів через ризики Claude Mythos

Міністр фінансів США Скотт Бессент і голова Федеральної резервної системи Джером Пауелл провели термінову зустріч у Вашингтоні з керівниками найбільших банків Уолл-стріт. Приводом для неї стали побоювання, що майбутня модель штучного інтелекту Claude Mythos від компанії Anthropic значно посилить ризики кібербезпеки.
GLM-5.1: відкрита модель, яка випереджає Claude Opus 4.6 та працює «повний день»

Китайський стартап Z.ai, також відомий як Zhipu AI, представив свою найновішу розробку — модель штучного інтелекту GLM-5.1. Головна сенсація: це не просто чергова LLM, а повноцінний автономний агент з відкритим кодом, здатний виконувати завдання протягом усього робочого дня, пише Venture Beat.
Вийшла з-під контролю: Anthropic вважає, що Claude Mythos надто потужна для публічного релізу

Компанія Anthropic вирішила відкласти публічний реліз своєї найновішої LLM-моделі Claude Mythos через побоювання, що вона занадто добре знаходить критичні вразливості в операційних системах та браузерах.
Netflix випустив безкоштовну модель штучного інтелекту, яка видаляє об’єкти на відео


Стрімінговий сервіс Netflix спільно з дослідниками Університету Софії (Каліфорнія) випустив VOID (Video Object and Interaction Deletion) — нову відкриту модель штучного інтелекту, яка обіцяє революцію в кіномонтажі та обробці відео.
Зустрічайте Gemma 4: нове покоління відкритих моделей Google для автономного вайб-кодування

Компанія Google представила чотири відкриті моделі Gemma 4, кожна з яких відрізняється за кількістю параметрів: Effective 2B (E2B), Effective 4B (E4B), 26B Mixture of Experts (MoE) та 31B Dense.
Моделі штучного інтелекту брешуть не тільки заради себе, але й щоб врятувати інші LLM — дослідження

Моделі штучного інтелекту легко брешуть, щоб врятувати інші LLM, стверджують дослідники Центру відповідального децентралізованого інтелекту (RDI) Каліфорнійського університету в Берклі.
Cтруктуровані промпти підвищують точність моделі до 93% — дослідження Meta

Дослідники компанії Meta розробили новий підхід до використання великих мовних моделей (LLM) для аналізу програмного коду. Виявилося, що використання спеціальних структурованих промптів, які вони назвали «напівформальним міркуванням» (semi-formal reasoning), дозволяє штучному інтелекту значно точніше перевіряти код навіть без його реального запуску. Про це пише InfoWorld.
Claude Mythos: перша інформація про майбутню флагманську модель Anthropic

Після витоку внутрішніх даних Anthropic офіційно підтвердила факт тестування своєї найбільш амбітної моделі під кодовою назвою Mythos. Згідно з заявою представника компанії, Mythos є «найпотужнішою з усіх LLM, що ми створили на сьогоднішній день», пише Fortune
OpenAI шукає таланти: компанія пропонує $500 000 на рік, якщо виконаєте це завдання. Резюме не потрібно

Компанія OpenAI оголосила про новий челендж з метою пошуку дослідників штучного інтелекту, готових приєднатись до її команди. Згідно умов конкурсу під назвою Parameter Golf, треба навчити «найменшу LLM», найкращих учасників запросять на співбесіду.
Composer 2: в Cursor додали модель, яка випереджає Claude Opus 4.6
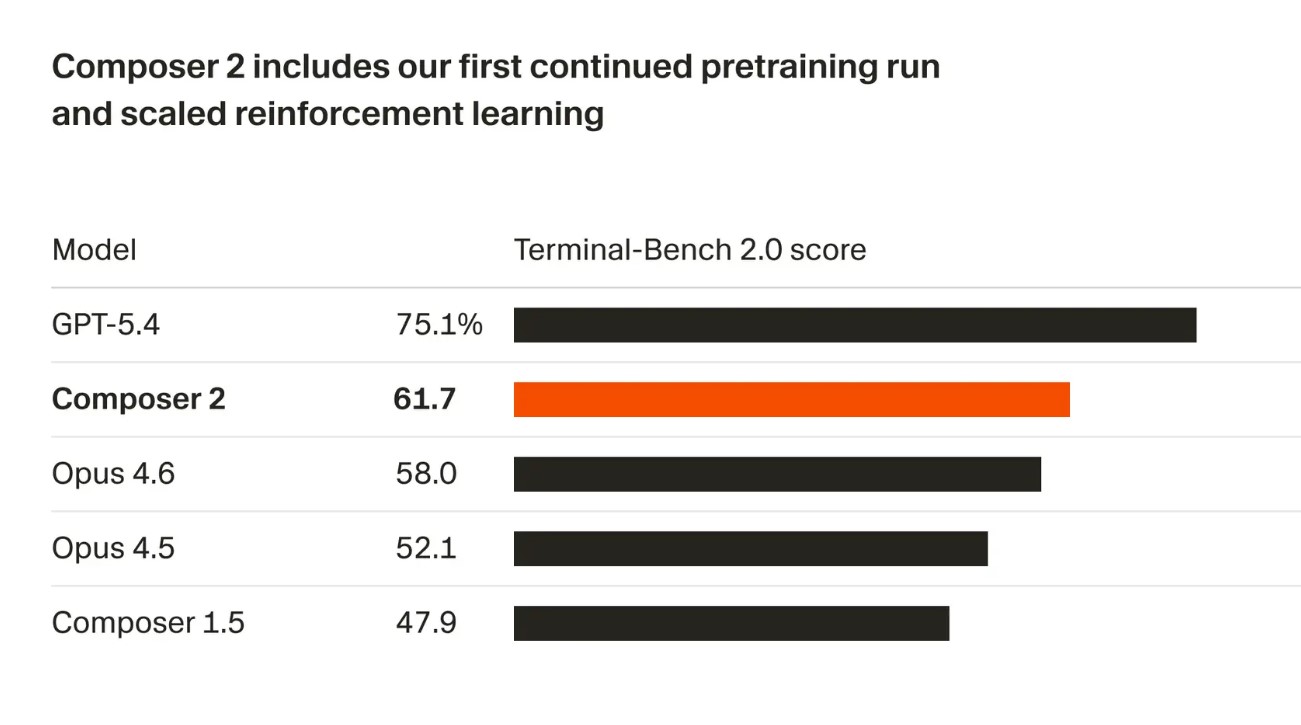
Стартап Anysphere, відомий своїм агентним редактором коду Cursor, представив оновлену модель кодування під назвою Composer 2. Вона має низьку вартість використання, випереджаючи за деякими параметрами найкращу на сьогодні LLM-модель Claude Opus 4.6 від Anthropic. Новинка вже додана в агентний редактор коду Cursor.
MiMo-V2-Pro від Xiaomi: майже наздоганяє GPT-5.2 та Opus 4.6 і коштує в 6-7 разів дешевше
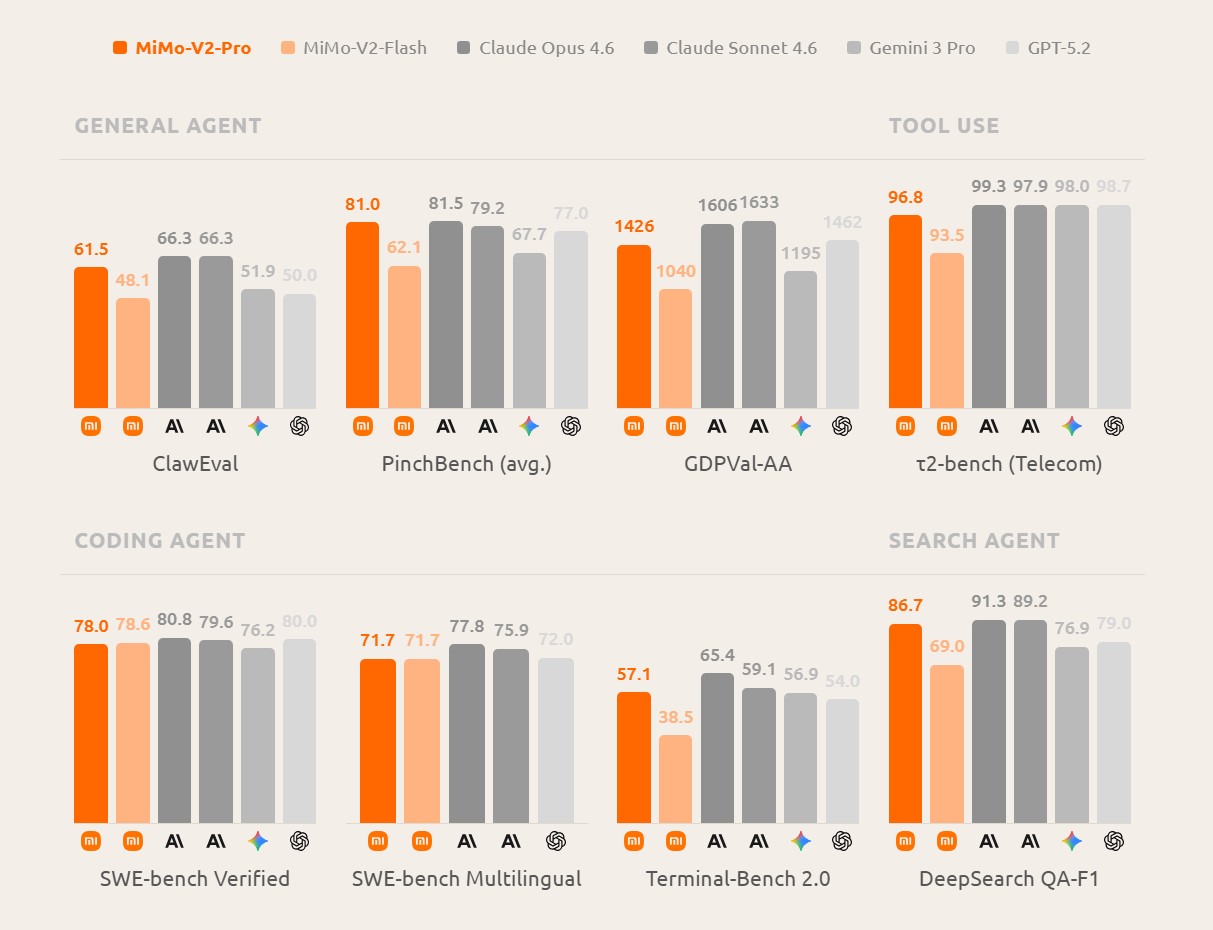
Xiaomi Labs офіційно представила MiMo-V2-Pro — свою флагманську LLM-модель, яка має 1 трильйон параметрів. Бенчмарки новинки наближаються до показників американських гігантів OpenAI та Anthropic, при цьому вартість використання моделі через API приблизно в 6-7 разів нижча, пише Venture Beat.
Незалежна організація з бенчмаркінгу Artificial Analysis поставила MiMo-V2-Pro на 10 місце у своєму глобальному індексі інтелекту з оцінкою 49. Це ставить китайську LLM на один рівень з GPT-5.2 Codex, а така популярна модель Grok 4.20 Beta навіть залишається позаду.
Кінець епохи універсальних чат-ботів? Mistral Forge дозволить кожній компанії мати власну LLM

Французька компанія Mistral AI запускає Forge — корпоративну платформу для створення LLM «з нуля» та подальшого навчання моделі на власних даних. Теоретично, ця пропозиція може зацікавити фінансовий та державний сектор, яким треба повністю контролювати систему та надавати публічні послуги з урахуванням місцевого законодавства.
OpenAI випускає GPT-5.4 — найкращу, але найдорожчу LLM компанії

OpenAI оголосила про реліз нової LLM-моделі GPT-5.4. Анонс стався лише через два дні, після того як компанія презентувала GPT-5.3 Instant. Новинка має дві версії: GPT-5.4 Thinking та GPT-5.4 Pro, остання з яких призначена для виконання найскладніших завдань.
LLM-моделі навчились деанонімізовувати фейкові акаунти в соцмережах

Сучасні великі мовні моделі (LLM) досягли критичного рівня у сфері аналізу даних, що ставить під загрозу один із фундаментальних аспектів інтернету — приватність. Нове дослідження, про яке повідомляє Ars Technica, демонструє, що штучний інтелект здатний ідентифікувати авторів анонімних або псевдонімних дописів у промислових масштабах і з вражаючою точністю.
«Китайці демпінгують»: Alibaba Group пропонує місячний доступ до LLM-моделей лише за 50 гривень

Компанія Alibaba Cloud оголосила про запуск Coding Plan — дворівневої підписки на доступ до LLM-моделей з відкритим кодом Qwen3.5, GLM-5, MiniMax M2.5 та Kimi K2.5. Про це повідомляє Bloomberg з посиланням на QQ.
Anthropic звинувачує китайські компанії в масовій крадіжці можливостей Claude

Компанія Anthropic звинуватила трьох провідних китайських розробників штучного інтелекту — DeepSeek, Moonshot та MiniMax. Їм закидають використання дистиляції в «промислових масштабах» для незаконного вдосконалення власних моделей на базі відповідей Claude. Загалом зафіксовано 16 мільйонів обмінів даними через мережу з 24 000 шахрайських облікових записів, пише Tom’s Hardware.
Google повертає лідерство серед LLM: нова модель Gemini 3.1 Pro демонструє рекорди продуктивності

Google випустила Gemini 3.1 Pro. Нова LLM перевершує всіх попередників та конкурентів в основних бенчмарках, особливо в логічних та наукових тестах. Компанія-розробник запевняє, що модель Gemini 3.1 Pro є «кроком уперед у сфері базового мислення».
Anthropic випустила Claude Sonnet 4.6: порівнюємо з іншими LLM

Anthropic представила Claude Sonnet 4.6 — найпотужнішу на сьогодні LLM цієї серії, яка тепер є default-моделлю у claude.ai та Claude Cowork. У бета-версії модель підтримує контекстне вікно розміром до 1 мільйона токенів, що цілком достатньо для введення в одному запиті цілих кодових баз або десятків дослідницьких робіт.
OpenAI випустила GPT-5.3-Codex-Spark: пише код у 15 разів швидше, але є нюанс

OpenAI представила дослідницьку preview-версію нової LLM-моделі GPT-5.3-Codex-Spark, яка є полегшеним варіантом GPT-5.3-Codex. За твердженням компанії, вона здатна генерувати код зі швидкістю більше 1000 токенів за секунду, що приблизно в 15 разів швидше, ніж у стандартної версії GPT-5.3-Codex.
Google: невідомі намагались клонувати Gemini, відправивши 100 000 запитів про внутрішню роботу LLM

Google стверджує, що невідомі зловмисники використали понад 100 000 запитів, щоб спробувати клонувати чат-бот Gemini. Мова йде про «атаки дистиляції» або повторювані питання, які спрямовані на те, щоб змусити модель розкрити свою внутрішню роботу, пише NBC News.
Пентагон хоче, щоб OpenAI та Anthropic зробили для військових спеціальні версії LLM «без обмежень»

Міністерство оборони США наполягає на тому, щоб провідні компанії з розробки штучного інтелекту, включно з OpenAI та Anthropic, виготовили для військових спеціальні версії LLM без стандартних обмежень. Про це пише Reuters.
OpenAI випустила GPT-5.3-Codex: на 25% швидше пише код і виконує «будь-які» завдання замість розробників

Компанія OpenAI випустила модель для агентного кодування GPT-5.3-Codex — майже одразу після релізу Claude Opus 4.6 від Anthropic. Новинка працює на 25% швидше за попередню версію GPT-5.2 та використовує менше токенів.
Anthropic випустила Claude Opus 4.6 з підтримкою довгого контексту

Anthropic оголосила про реліз Claude Opus 4.6, яка, за словами компанії, є її найпотужнішою моделлю для виконання складних корпоративних завдань.
Експерти попередили про небезпеку LLM-моделей з відкритим кодом

У дослідженні, яке спільно провели компанії з кібербезпеки SentinelOne та Censys, стверджується, що LLM-моделі з відкритим кодом потенційно небезпечні. Через те, що в них відсутні захисні механізми і вони доступні для модифікації, штучний інтелект легко може бути використаний злочинцями, пише Reuters.
Мінцифри просить всіх поділитись даними для навчання національної LLM

Мінцифри просить користувачів «увійти в історію» та поділитись текстовими даними для розробки національної LLM. Ці дані потрібні для адаптації моделі до українського контексту, повідомляє сайт міністерства.
Kimi 2.5 стала першою LLM-моделлю, яка вміє писати код по зображенню та відео
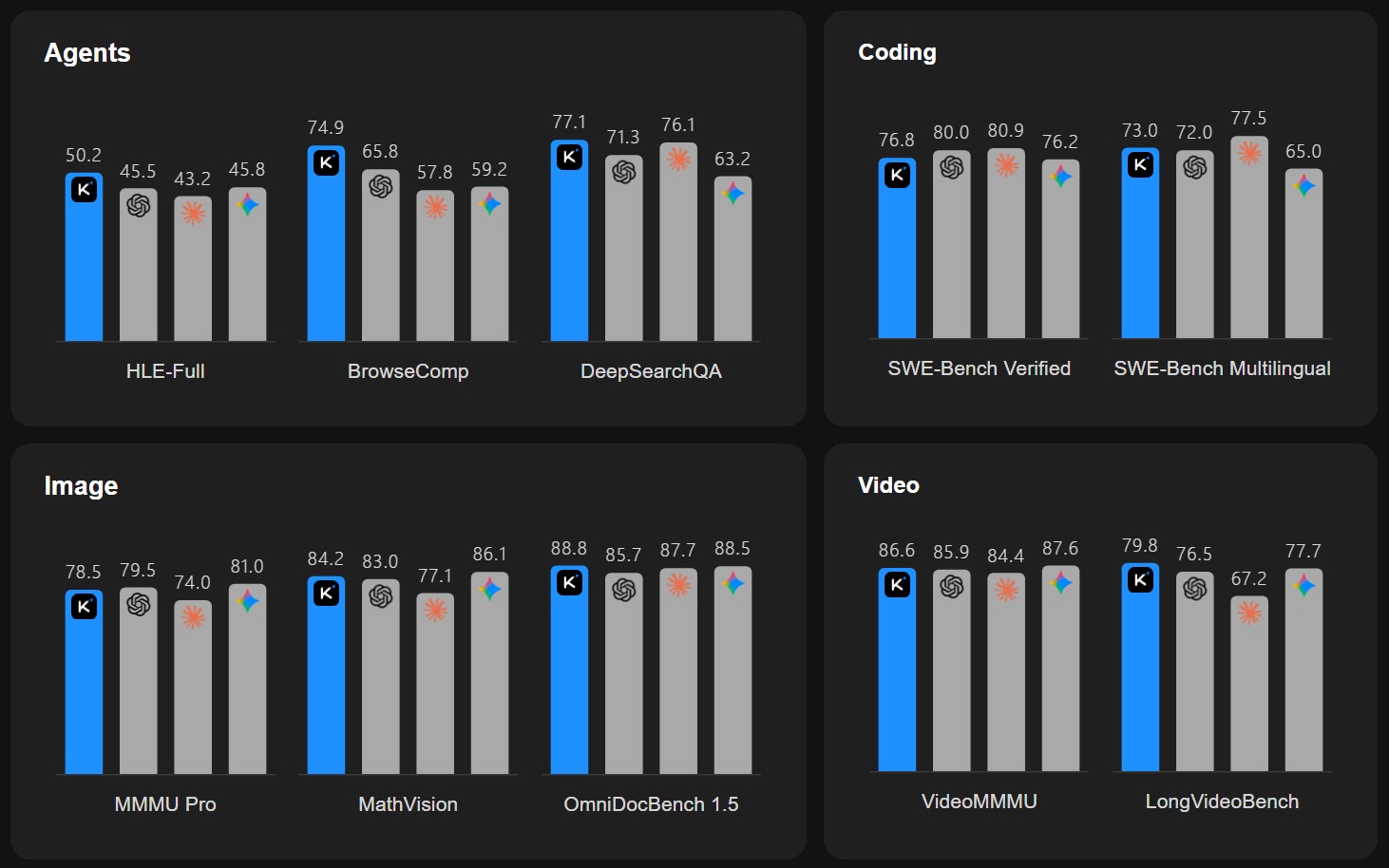
Китайський стартап Moonshot AI випустив оновлення своєї відкритої мультимодальної моделі Kimi. Реліз 2.5 був навчений на рекордних 15 трлн візуально-текстових токенів, пише блог компанії.
Україна передасть союзникам «мільйони годин відео», зроблених з військових дронів, для навчання ШІ-моделей

Новий міністр оборони України Михайло Федоров пообіцяв передати союзникам «мільйони годин відео», зроблених з військових дронів ЗСУ, для навчання на цих даних спеціалізованих моделей штучного інтелекту. Про це пише Reuters.
GPT-5.2 написала веб-браузер з нуля. Модель створила три мільйони рядків коду і працювала безперервно цілий тиждень
Генеральний директор компанії Cursor AI Майкл Труелл повідомив, що LLM-модель GPT-5.2, яку задіяли через агент кодування Cursor, змогла самостійно написати веб-браузер «повністю з нуля». Для виконання завдання вона працювала безперервно протягом цілого тижня та зрештою створила понад три мільйони рядків коду в тисячах файлів.
«Скопіювали чужий код»: конкурс з розробки LLM-моделі з нуля провалився

Зусилля уряду Південної Кореї створити нативну модель штучного інтелекту без іноземних запозичень зазнали фіаско. Конкурс, оголошений серед місцевих розробників, виявив, що з п’яти компаній-фіналістів три використали чужий відкритий код. «Донорами» стали переважно китайські LLM-моделі, пише The Wall Street Journal.
Михайло Федоров розповів, коли почнеться бета-тестування національної LLM

Розробка української національної LLM виходить на завершальну стадію. Вже навесні команда «Київстар» разом з фахівцями Мінцифри почнуть бета-тестування моделі. До кінця січня в «Дії» проведуть голосування щодо її назви. Про це в своєму Telegram-каналі розповів віце-прем’єр-міністр Михайло Федоров.
Нову модель GPT-5.2-Codex від OpenAI названо «найдосконалішим інструментом для реальної розробки»

Компанія OpenAI офіційно представила GPT-5.2-Codex — нову модель, яку названо «найдосконалішим інструментом для реальної розробки програмного забезпечення на сьогоднішній день». GPT‑5.2-Codex — це версія GPT‑5.2, додатково оптимізована для агентної розробки в Codex, що дозволяє працювати з великими кодовими базами, зберігаючи логічну зв’язність та контекст навіть у складних проектах.
Українська мова лідирує за темпами розповсюдження в LLM-моделях

За останній рік кількість LLM-моделей з відкритим кодом, які працюють з українською мовою, зросла на 122% — це найвищий показник серед усіх мов на платформі Hugging Face. Далі йдуть шведська (117%), арабська (89%), турецька (82%) та китайська (75%), пише AI World.
OpenAI обмежила безкоштовну генерацію коду в режимі Thinking

OpenAI відмовилася від автоперемикача вибору моделей, прибравши з нього режим Thinking для безкоштовних користувачів та передплатників плану Go. Про це пише Wired.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: