
Привіт усім! Мене звати Владислав Хирса, я — Software Engineer у Grid Dynamics. Сьогодні я розповім вам, як за допомогою Node.js створити потік відеоданих. Стаття буде корисною для тих, хто ще тільки розбирається у темі Streams in Node.js (наприкінці буде трохи важливої теорії).
Створити потік даних у Node.js зараз просто, але чи все ми розуміємо про те, яким чином працює ця абстракція?
Знайти код ви можете за посиланням.
Почнемо!
Спочатку запустимо наш сервер, перебуваючи у папці проєкту, командою npm start.
Далі наш сервер запуститься за адресою http://localhost:8000/. Перейшовши за посиланням, у вашому браузері має з’явитися вкладка такого змісту:

Тут ми можемо бачити в дії наш проєкт. І тепер те, задля чого ми тут — дізнатися, як все працює.
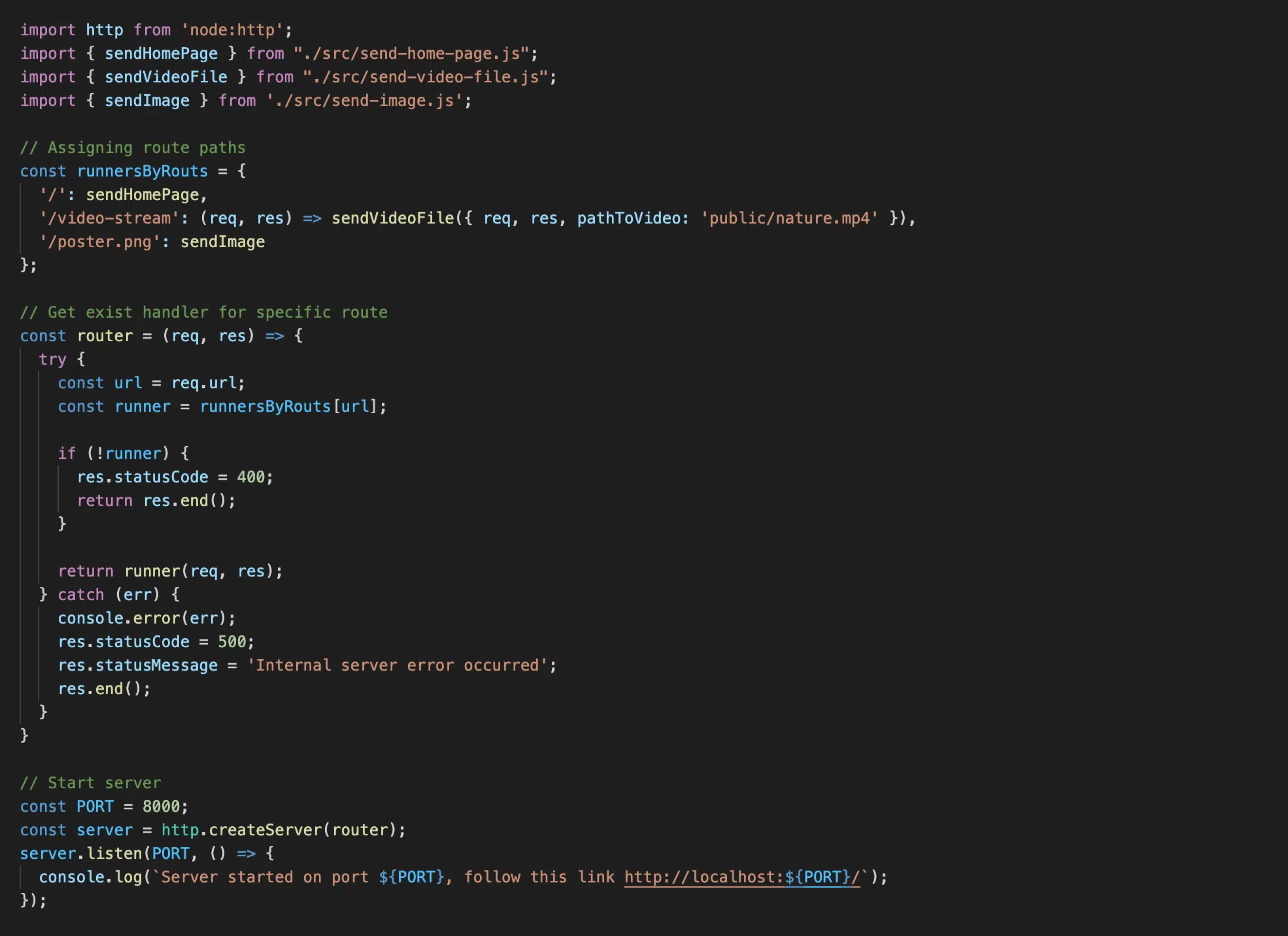
Файл index.js
Натисніть, щоб роздивитися
Тут ми створили простий сервер, функцією зворотного виклику призначили функцію router, яка отримує параметри request і response. Далі ми перевіряємо, чи маємо по отриманому request.url збіги в нашому об’єкті runnersByRouts за даним іменем ключа. Якщо так — то викликаємо відповідну функцію, якщо ні — то повертаємо відповідь про помилку до клієнта.
При відкритті вкладки в браузері за нашим посиланням до нашого сервера надходить запит з url /, і ми віддаємо нашу сторінку, файл index.html.
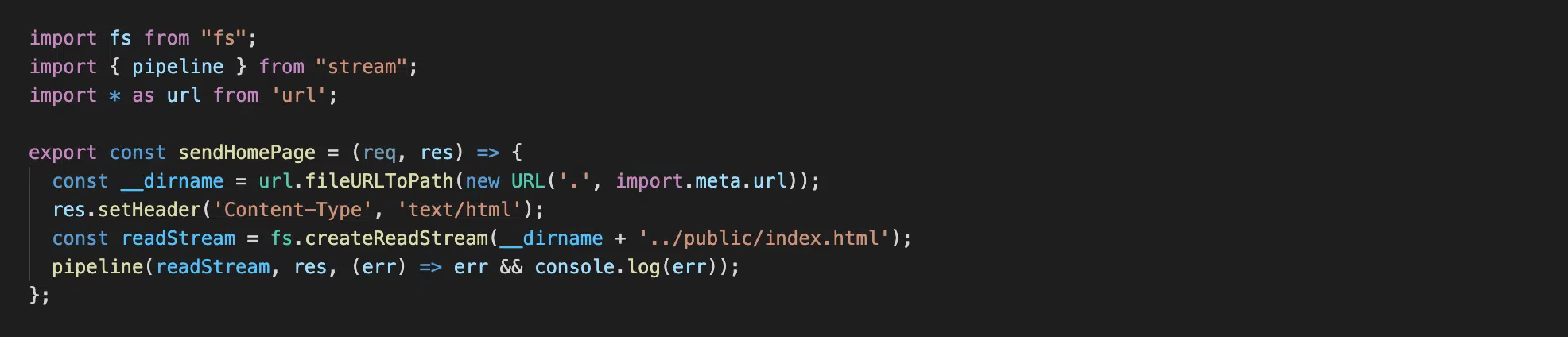
Файл src/send-home-page.js
Натисніть, щоб роздивитися
Спочатку ми знаходимо шлях до нашої папки за допомогою url.fileURLToPath(new URL('.', import.meta.url)), назначаємо тип контенту, який збираємось надіслати клієнту res.setHeader('Content-Type', 'text/html'), далі створюємо читабельний потік fs.createReadStream(__dirname + '../public/index.html') і на останньому рядку викликаємо наш потік за допомогою функції pipeline().
Тож поки що все зрозуміло, але трішки нижче ми поговоримо, як воно все працює трохи детальніше.
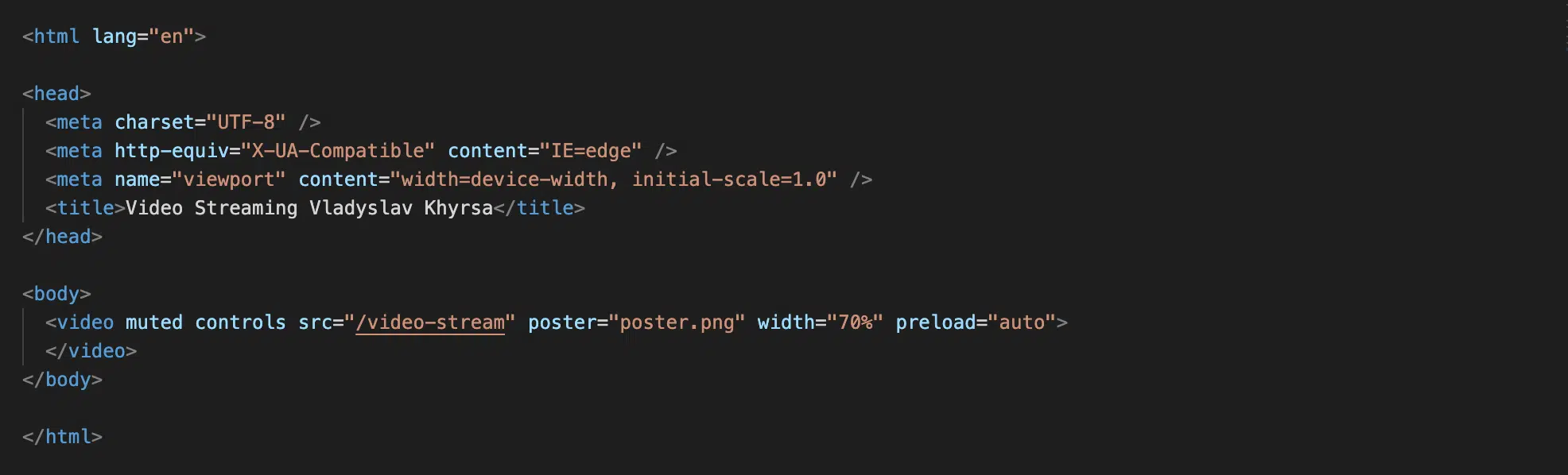
Файл index.html
Натисніть, щоб роздивитися
Розглянемо декілька важливих для нас атрибутів в html елементі <video>:
src="/video-stream"— при рендерингу нашої сторінки в браузері ми звертаємось до нашого серверу за адресоюhttp://localhost:8000/video-streamі отримуємо наше відео.controls— цей атрибут дає користувачу можливість мати контроль над відео (старт/пауза, звук тощо).preload="auto"— у специфікації вказано те, що весь відеофайл може завантажитись навіть якщо користувач не буде використовувати його. Але на практиці все залежить від браузера і відбуватиметься, скоріш за все, більш динамічно. Наприклад, так — ваше відео буде завантажено приблизно на 1 хв. наперед і через кожні 5 секунд пройденого відео дозавантажаться ще 5 секунд і т.д.
Тож нам надходить запит з url /video-stream і ми викликаємо нашу функцію sendVideoFile.
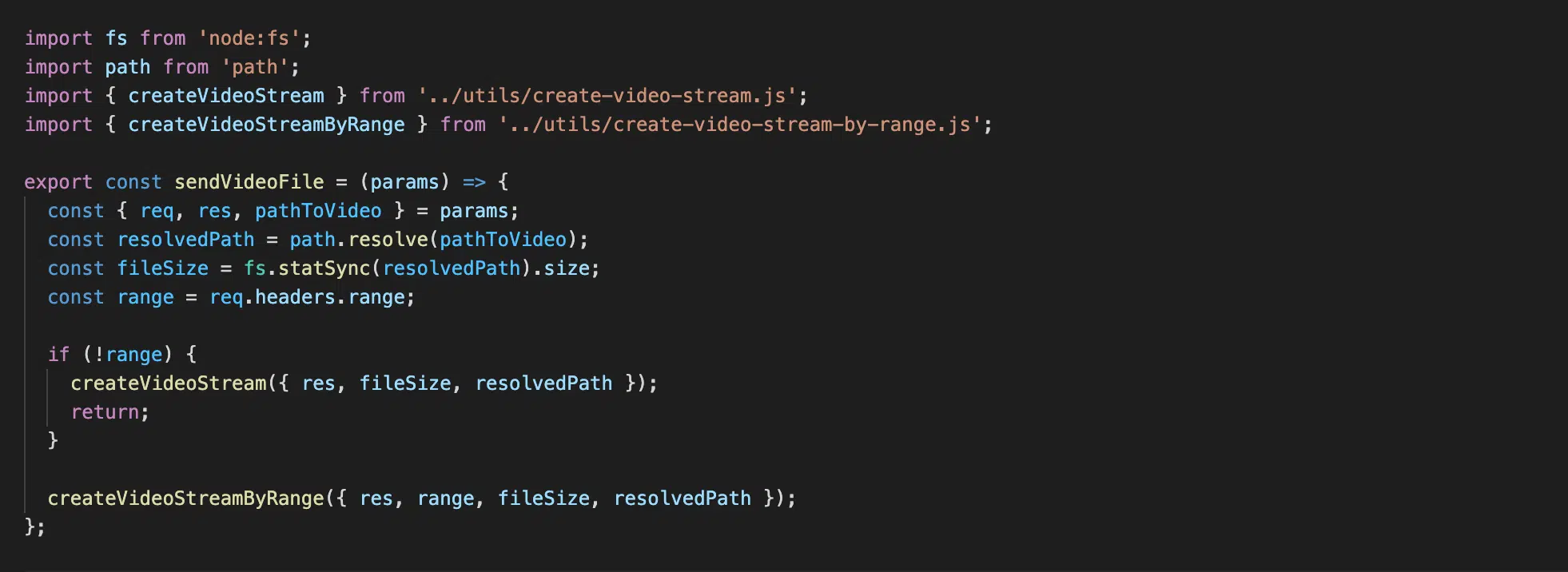
Файл src/send-video-file.js
Натисніть, щоб роздивитися
У нашій функції sendVideoFile все починається з того, що:
- Ми створюємо абсолютний шлях до файлу — шлях, який нам вказали в параметрі
pathToVideo. Булоpublic/nature.mp4— стало/your_folder/your_folder/project_folder/public/nature.mp4. fs.statSync(resolvedPath).size— дізнаємося розмір файлу в байтах.req.headers.range— отримуємо параметрrange (bytes=12582912-), тобто те, з якої позиції треба завантажувати відео в байтах.
Залежно від браузера і плеєра параметр range може бути null або, наприклад, bytes=123456-, тож у нас є дві різні функції для обробки цих насправді різних підходів.
Файл utils/create-video-stream.js
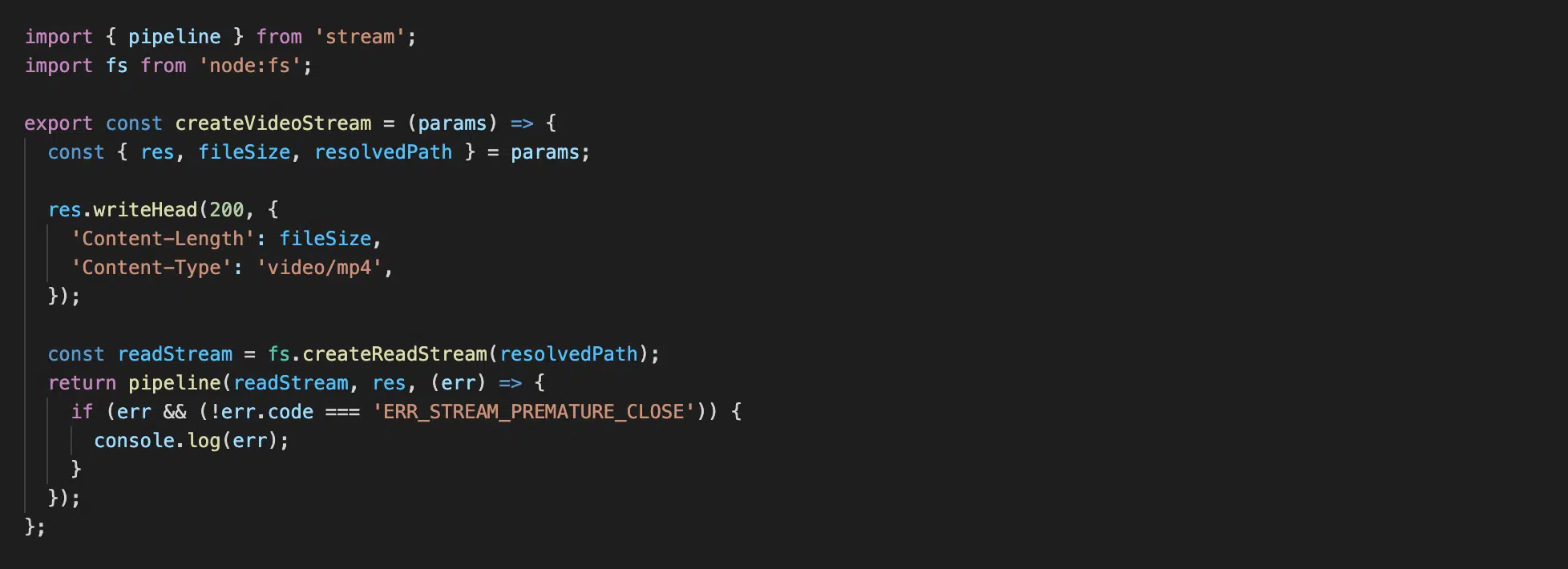
Натисніть, щоб роздивитися
Тут вже все просто — код схожий з тим, який ми вже розглядали в src/send-home-page.js. Єдина різниця в тому, що ми назначаємо обов’язкові заголовки Content-Type і Content-Length для того, щоб браузер розумів, якого типу ми надсилаємо йому інформацію і якого розміру. Це необхідно як для коректної роботи плеєра, так і для подальшої взаємодії плеєра з сервером під час наступних транзакцій даних.
І внизу також один із найчастіших випадків — коли параметр range існує.
Файл utils/create-video-stream-by-range.js
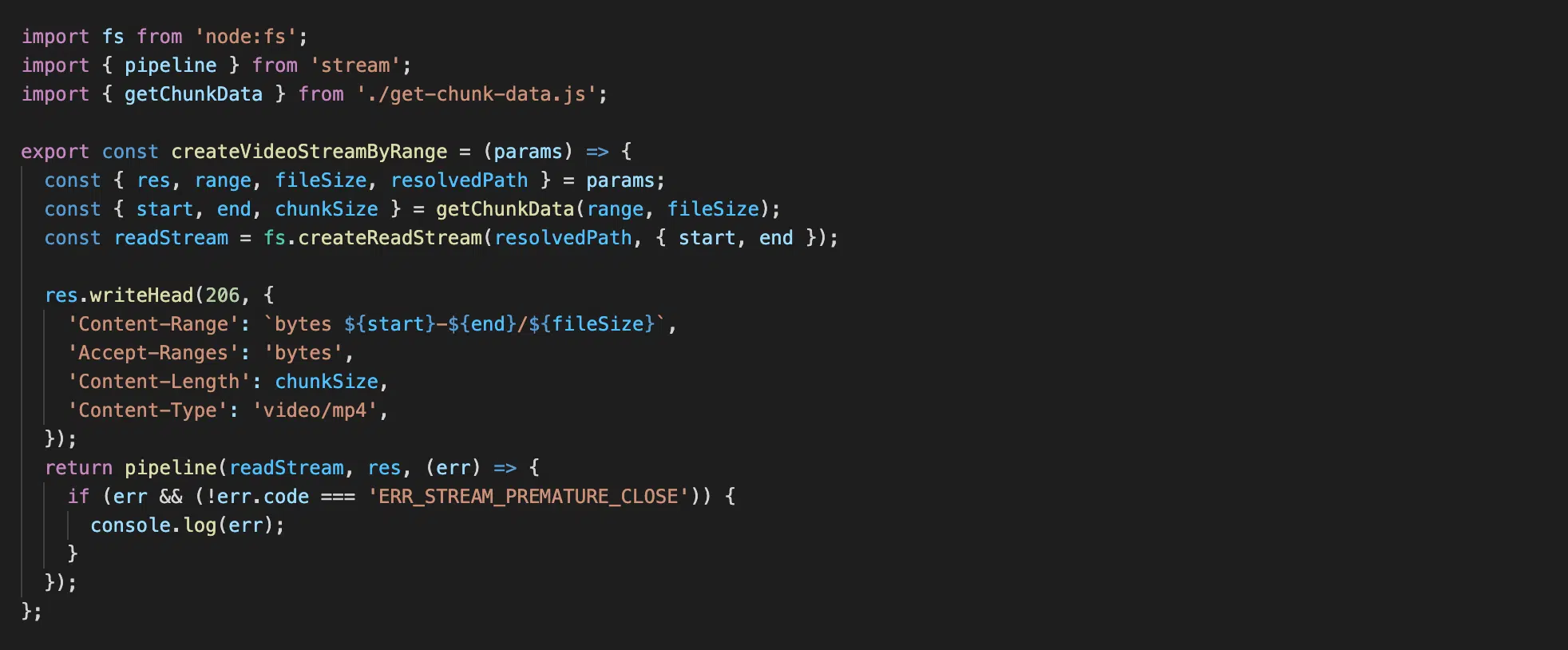
Натисніть, щоб роздивитися
Тут у нас є функція getChunkData, яка бере вхідний параметр range та fileSize та здійснює наступні кроки:
- Бере пару значень з
range = bytes=36634624-і отримує масивparts = [ '36634624', '' ]. - Обчислює значення
start = 36896768,end = 86890916,chunkSize = 49994149.
Файл utils/get-chunk-data.js
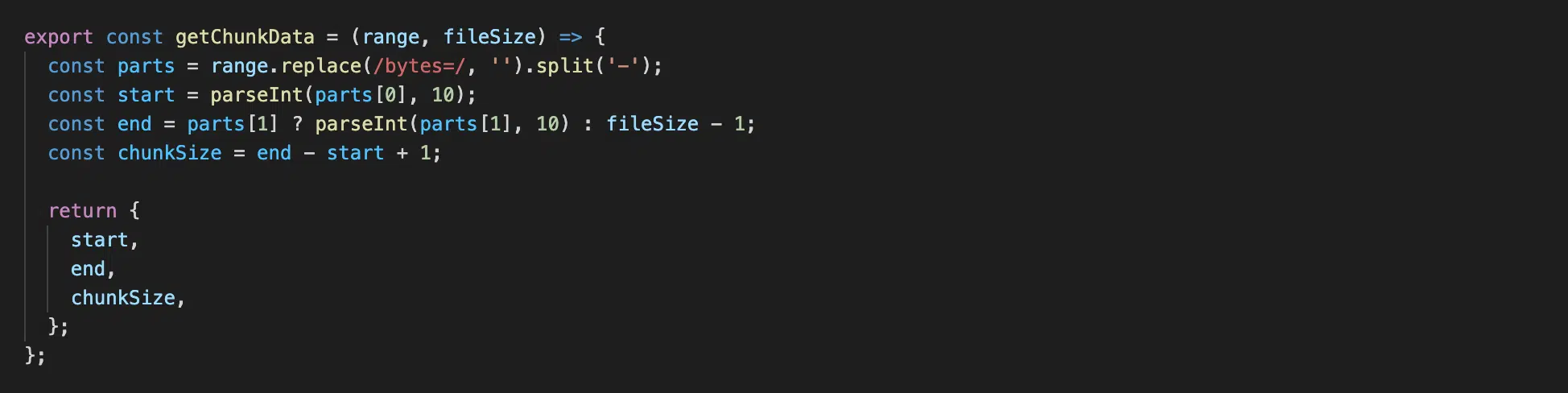
Натисніть, щоб роздивитися
Також в createVideoStreamByRange ми вказуємо обов’язковим статус відповіді 206, а також Content-Range — яку частину даних з усього відео ми відправляємо, а також Accept-Ranges — у якому форматі дані, які ми відправляємо.
Ще кілька доповнень, які корисно знати:
pipeline— чому краще використовуватиpipeline(), а не чергуpipe()при роботі з потоками. У функціїpipeline()останнім аргументом є функція зворотного виклику. Ми використовували її у вищезазначених прикладах коду. Якщо виникне помилка в будь-якому з переданих потоків, то ми її можемо обробити в одному місці. Такожpipeline()самостійно закриває всі закінчені, але не закриті запити до сервера. Наприклад, коли ми використовуємоsomeReadStream(path).pipe(res), то після помилки або закінчення передачі даних запит до сервера скоріш за все не зачинить, через що виникають незрозумілі та дуже вагомі помилки та втрата оперативної пам’яті. Про це ви можете почитати детальніше тут.ES modules— щоб використати імпортування функціоналу за допомогоюimports, в js-файлах нам потрібно вказати вpackage.jsonтип таким чином{ "type": "module" }, але такі змінні, як__dirnameта__filenameне існують вES modules, а є можливістюCommonJS. З цим ви можете ознайомитись за посиланням з офіційної документації. Тож знайти шляхи ми можемо таким чином:
const __filename = url.fileURLToPath(import.meta.url);
const __dirname = url.fileURLToPath(new URL('.', import.meta.url));
highWaterMark— це значення розміру внутрішнього буферу, тобто кількість даних у байтах, які ми можемо прочитати за один раз, тобто одинchunkданих (за замовчуванням він 64kB). Також значенняhighWaterMarkми можемо змінити при створенні потокуfs.createReadStream(path, { highWaterMark: 2 }), тепер ми будемо зчитувати наш файл по два символи за раз, а також можемо дізнатися його розмір таким чином:readStream.readableHighWaterMark, значення за умовчанням буде 65536 байтів.

Натисніть, щоб роздивитися
Як працює потік і відправлення даних в деталях?
Cпершу ми створюємо потік зі зчитування файлу і призначаємо його в зміну readStream, після цього використовуємо його в функції pipeline(), далі chunk даних передається до потоку res (тобто response, якщо повністю) і тоді res його отримує і відправляє клієнту за допомогою res.write(chunk). Щоразу коли ми читаємо і передаємо йому наш chunk даних, то в кінці, коли вже немає даних для зчитування, викликається подія end для кожного потоку і функція pipeline() самостійно закриває їх. Що дуже важливо, у випадку з res після останнього викликається res.end() і наш запит до сервера успішно закінчується.
На цьому все, дякую всім за увагу. Продуктивного вам кодування 😉
Цей матеріал – не редакційний, це – особиста думка його автора. Редакція може не поділяти цю думку.








Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: