LLM-моделі навчились деанонімізовувати фейкові акаунти в соцмережах
Сучасні великі мовні моделі (LLM) досягли критичного рівня у сфері аналізу даних, що ставить під загрозу один із фундаментальних аспектів інтернету — приватність. Нове дослідження, про яке повідомляє Ars Technica, демонструє, що штучний інтелект здатний ідентифікувати авторів анонімних або псевдонімних дописів у промислових масштабах і з вражаючою точністю.
Як працює «цифровий відбиток» тексту?
Кожна людина має унікальний стиль письма, відомий як стилометрія. Це поєднання вибору слів, специфічних зворотів, структури речень, пунктуації та навіть типових помилок. Раніше лінгвістичний аналіз для встановлення авторства вимагав залучення висококваліфікованих експертів і багато часу. Проте сучасні LLM можуть обробляти колосальні масиви даних миттєво, виявляючи зв’язки між різними фрагментами тексту, написаними однією особою під різними іменами.
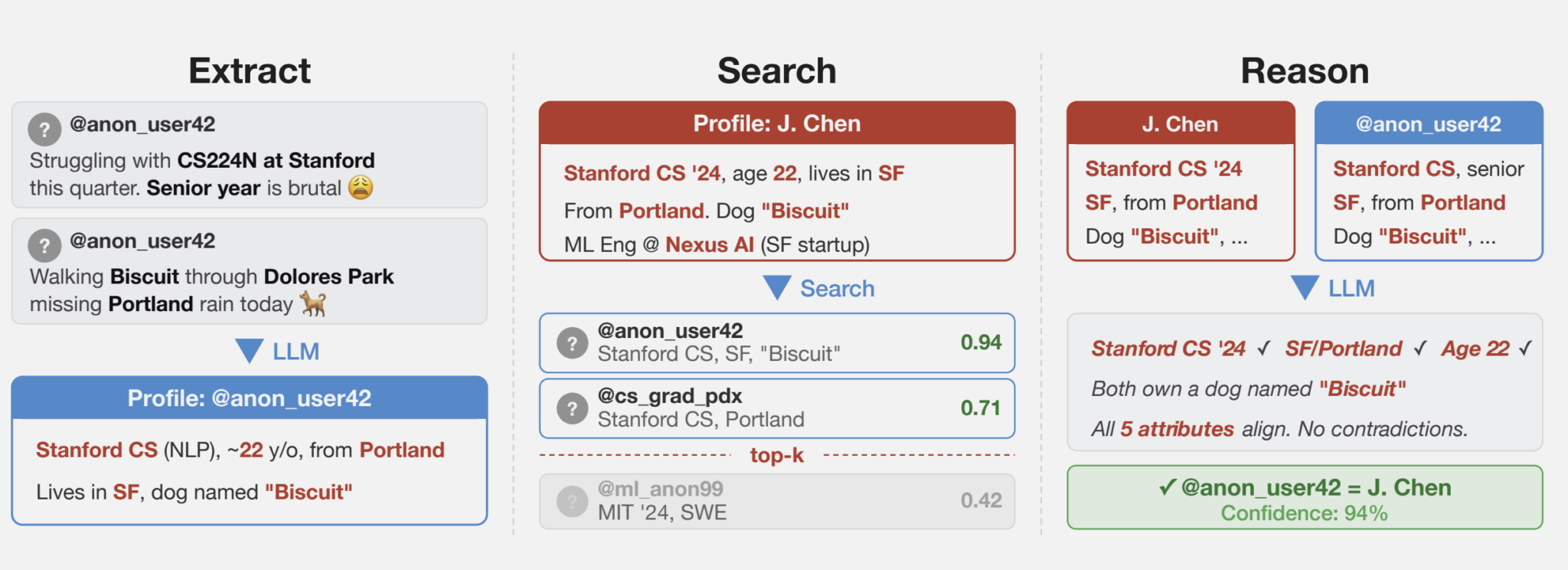
Приклад роботи системи деанонімізації
Дослідники з’ясували, що LLM можуть успішно пов’язувати анонімні профілі на публічних платформах (наприклад, Reddit) із реальними особистостями. Для цього модель порівнює стиль дописів із відкритими даними, де ідентичність користувача підтверджена — професійними профілями в LinkedIn, науковими статтями або особистими блогами.
Найбільш цікаво, що цей процес легко автоматизується. Тепер можна аналізувати мільйони акаунтів одночасно, і це робить нову технологію ідеальним і дешевим інструментом для стеження. Однак новинка має й свої ризики для кількох категорій:
- Інформатори та журналісти: Безпека людей, які викривають корупцію чи злочини, часто базується на анонімності.
- Політичні активісти: У країнах із жорсткою цензурою ідентифікація за стилем написання текстів може стати інструментом для переслідувань.
- Приватність: Компанії можуть використовувати ці дані для створення глибинних психологічних портретів без згоди користувачів.
Чи існує захист від деанонімізації?
Традиційні методи обфускації, такі як заміна окремих слів синонімами або використання онлайн-перекладачів для зміни структури (так званий «back-translation»), виявляються малоефективними проти потужних LLM. Автори дослідження зазначають, що для збереження приватності потрібні нові інструменти — спеціальні ШІ-помічники, які будуть «переписувати» текст, повністю вимиваючи з нього індивідуальні стилістичні ознаки, але зберігаючи первинний сенс.
Нагадаємо, днями стало відомо, що невідомий хакер змусив LLM стати його спільником у нападі на уряд Мексики.
Підписуйтесь на нас у соцмережах: Telegram | Facebook | LinkedIn








Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: