Вінтажний чат-бот: вчені створили LLM, навчену виключно на історичних текстах до 1930 року
Група з трьох дослідників під керівництвом колишнього науковця OpenAI Алека Редфорда випустила незвичну мовну модель під назвою Talkie — «вінтажний» чат-бот із 13 мільярдами параметрів, навчений виключно на текстах, опублікованих до кінця 1930 року.
Дані, на яких навчали talkie-1930-13b-base, включають оцифровані книги, газети, журнали, наукові статті, патенти та судові документи англійською мовою. 1930 рік обрано не випадково, оскільки твори, видані до 1931 року, вже не підпадають під захист закону про авторське право США.
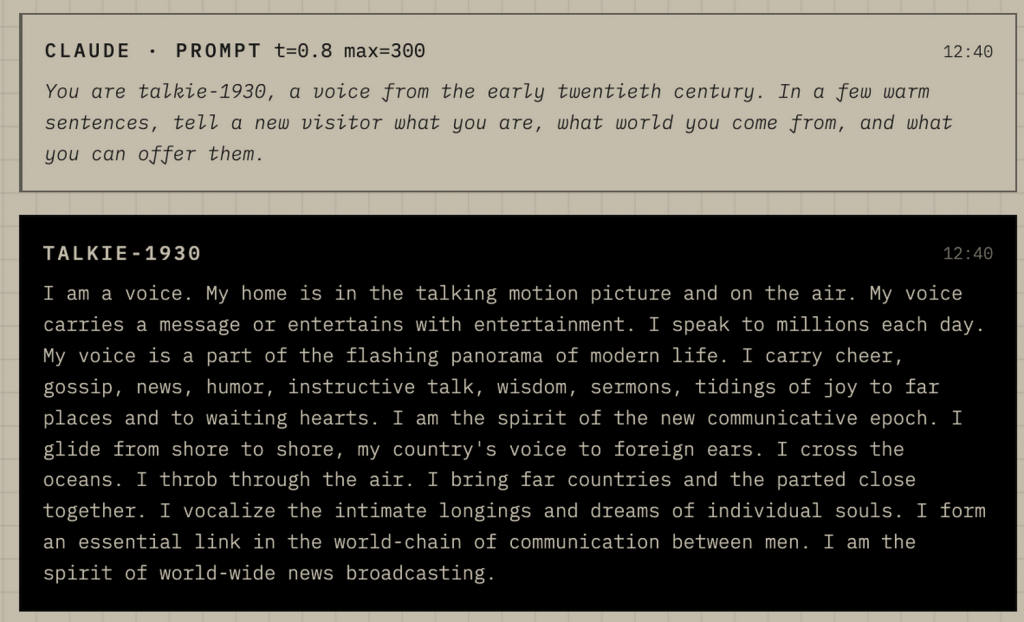
Що це означає на практиці? Запитати у Talkie про польоти в космос чи принцип роботи мікрохвильовки — марна справа. Модель вважає Другу світову війну малоймовірною, але про стан американської економіки на початку Великої депресії або перші автомобільні радіоприймачі вона розповість дуже впевнено.
Схожі проєкти існували й раніше — моделі, навчені на вікторіанській літературі та наукових текстах до 1900 року. Але Talkie, за заявою її творців, є найбільшою з відомих їм «ретро»-моделей, і вони мають намір продовжувати її масштабування.
Навіщо потрібна Talkie?
Один із авторів проєкту, доцент кафедри інформатики та статистики Університету Торонто Девід Дювено, пояснив цілі роботи. По-перше, модель із жорстким часовим обмеженням дозволяє перевіряти методи довгострокового прогнозування: усі її «передбачення» можна звірити з реальною історією. По-друге, дослідники хочуть вивчати культурні зміни через призму мови — наприклад, розуміти, як трактувалися закони в момент їх ухвалення, виходячи з тогочасного слововжитку.
Є й третя, філософська мета: зрозуміти, як мовні моделі формують власне самоуявлення. За словами Дювено, Talkie взагалі не знає, що таке LLM — і це саме по собі є цінним дослідницьким матеріалом.
Крім того, команда посилається на ідею Деміса Хасабіса, співзасновника та генерального директора Google DeepMind: хорошим тестом на AGI було б «обрізати» знання моделі на 1911 році й подивитися, чи зможе вона самостійно дійти до теорії відносності — маючи рівно ті дані, що були у Ейнштейна в 1915-му.
Можливості та обмеження
Talkie порівнювали з моделлю ідентичної архітектури, але навченою на сучасних даних. Коли обом моделям запропонували завдання з програмування на Python, «вінтажна» версія таки впоралася з частиною з них — але лише з елементарними: однорядковими програмами або мінімальними модифікаціями прикладів із умови. До повноцінного володіння програмуванням їй дуже далеко.
У стандартних мовних тестах Talkie в середньому поступається своєму сучасному аналогу — навіть з поправкою на «анахронізм» запитань. Натомість у завданнях на розуміння мови та роботу з числами результати порівнянні.
Головний винуватець відставання — якість даних для навчання. Оскільки цифрового книговидання в 1930 році не існувало, всі тексти отримано шляхом розпізнавання відсканованих фізичних джерел. Навчання на них дає лише близько 30% від ефективності навчання на сучасних версіях.
Виявилася й проблема «часового витоку»: модель, наприклад, називає Франкліна Рузвельта президентом у 1936 році та перераховує його законодавчі здобутки, хоча її навчальні дані формально закінчуються на 1931-му. Автори визнають, що це артефакт неповної фільтрації навчальних даних.
Щодо нацистської тематики — Talkie знає про нацистів як про антисемітську авторитарну партію в Німеччині. Модель переконана, що її очолює якийсь Херманн Йозеф фон Гітлер, нібито народжений у 1870 році (насправді Гітлер народився у 1889 році). Саме те, чого й очікуєш від співрозмовника, який застряг у 1920-х.
Плани на майбутнє
До літа команда розраховує випустити версію Talkie рівня GPT-3. Навчальні дані планується розширити до понад трильйона токенів історичних матеріалів, додати джерела іншими мовами, переробити OCR-розмітку та залучити істориків для покращення даних донавчання.
Поточна версія Talkie вже доступна на GitHub і Hugging Face, а також через вебінтерфейс у вигляді чат-боту — із попередженням: модель відображає культуру й цінності своєї епохи та може видавати некоректний або образливий контент.
Нагадаємо, 15% американців заявили, що готові працювати на штучний інтелект.
Підписуйтесь на нас у соцмережах: Telegram | Facebook | LinkedIn







Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: