

Gemini 2.5 Pro залишається найкращою LLM-моделлю для кодування. Новинка Grok 4 лише третя
Платформа для бенчмаркінгу великих мовних моделей LMArena опублікувала результати тестування Grok 4. Йдеться про API Grok 4 (grok-4-0709), яка зайняла 3-тє місце в загальному рейтингу Text Arena. Це великий стрибок у порівнянні з Grok 3, яка посіла 8-е місце, пише Bleeping Computer.
Згідно з тестами LMArena, Grok 4 отримала високі результати у всіх категоріях: №1 з математики, №2 з програмування, №3 у складних завданнях. Однак, варто зазначити, що протестована модель — це Grok 4, а не Grok 4 Heavy, яка значно краща за базову.
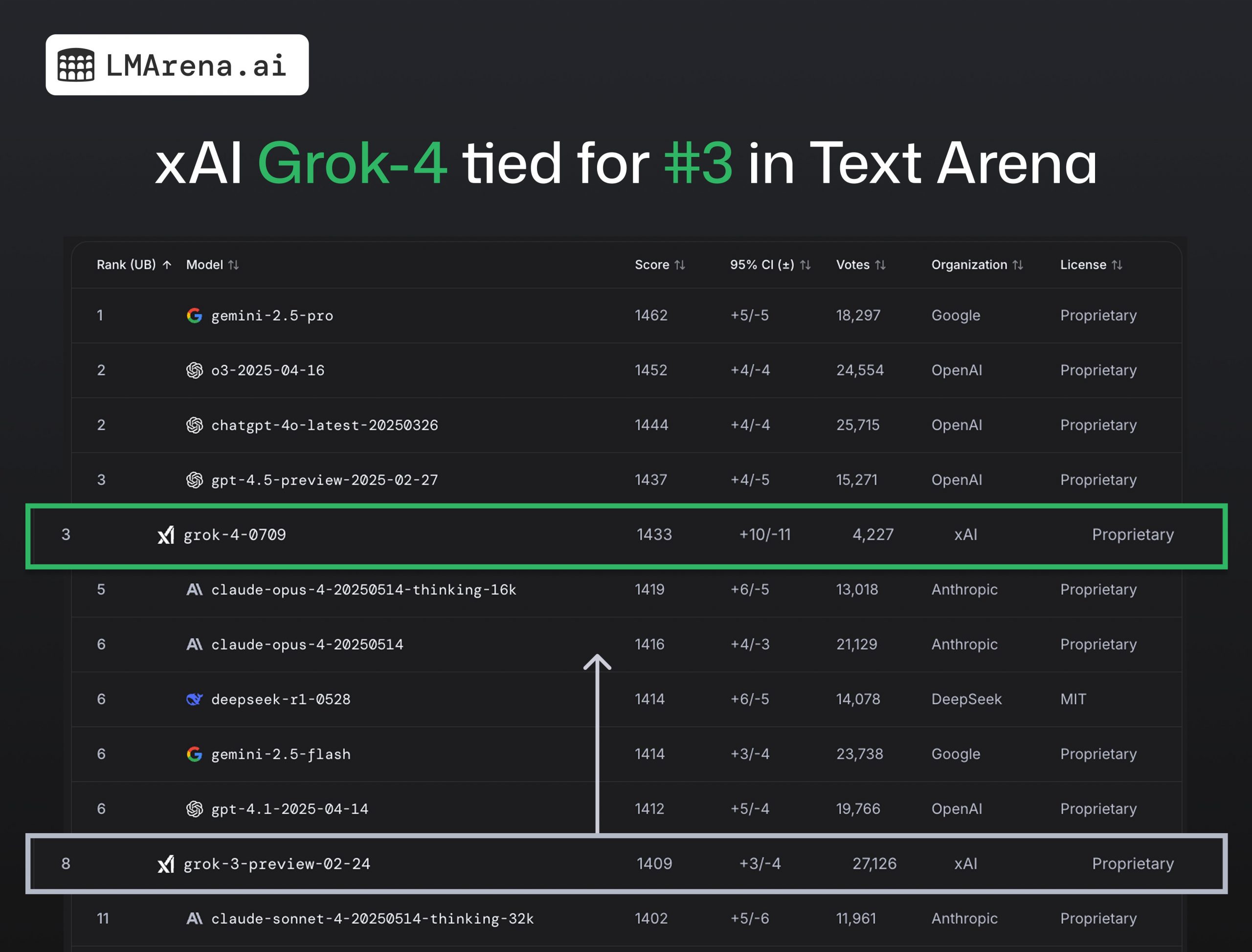
Результати можуть бути іншими з Grok 4 Heavy, яка використовує кілька агентів для міркування та порівняння результатів. На цей час модель Grok 4 Heavy ще не доступна на платформі API.
Gemini 2.5 Pro та Claude все ще залишаються найкращими моделями для кодування, але це може змінитися, коли в серпні xAI випустить Grok 4 Code — оптимізований інструмент для генерації та роботи з кодом. Також слід очікувати інструмент командного рядка, подібний до Gemini CLI та Claude Code.









Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: