Успіх DeepSeek-R1 ставить під загрозу багатомільярдну індустрію OpenAI
Реліз нової китайської моделі DeepSeek-R1, яка не поступається за продуктивністю моделям сімейства GPT, але значно перевищує їх за економічною ефективністю, викликав побоювання щодо перспектив багатомільярдної індустрії OpenAI. Як повідомляє Cointelegraph, на навчання DeepSeek-R1, яка має відкритий код, було витрачено лише $6 мільйонів та задіяна незначна кількість графічних процесорів.
Для порівняння: компанія OpenAI, яка надає платний доступ до ChatGPT, нещодавно закрила черговий раунд фінансування на суму $6,6 мільярдів з оцінкою капіталізації понад $157 мільярдів.
За словами венчурного капіталіста Ніка Картера, випуск безкоштовної моделі штучного інтелекту DeepSeek-R1, розробленої в Китаї, зруйнував уявні переваги Кремнієвої долини перед глобальними конкурентами. DeepSeek є доказом того, що OpenAI не має суттєвих переваг, а припущення Сема Альтмана щодо масштабування та вартості розробки моделей штучного інтелекту сильно завищені.
Додаткове занепокоєння, вже з боку виробника графічних процесорів Nvidia, полягає в тому, що DeepSeek-R1 настільки ефективний, що його полегшену версію з 1,5 мільярдами параметрів можна запустити на смартфоні.
У ключових тестах основні характеристики продуктивності DeepSeek-R1 відповідають або перевершують модель OpenAI-o1. Наприклад, у математичному тесті AIME 2024 китайська модель набрала бал Pass@1 79,8%, що трохи вище, ніж 79,2% у моделі o1. У тесті MATH-500 DeepSeek-R1 має результат 97,3% порівняно з 96,4% у конкурента.
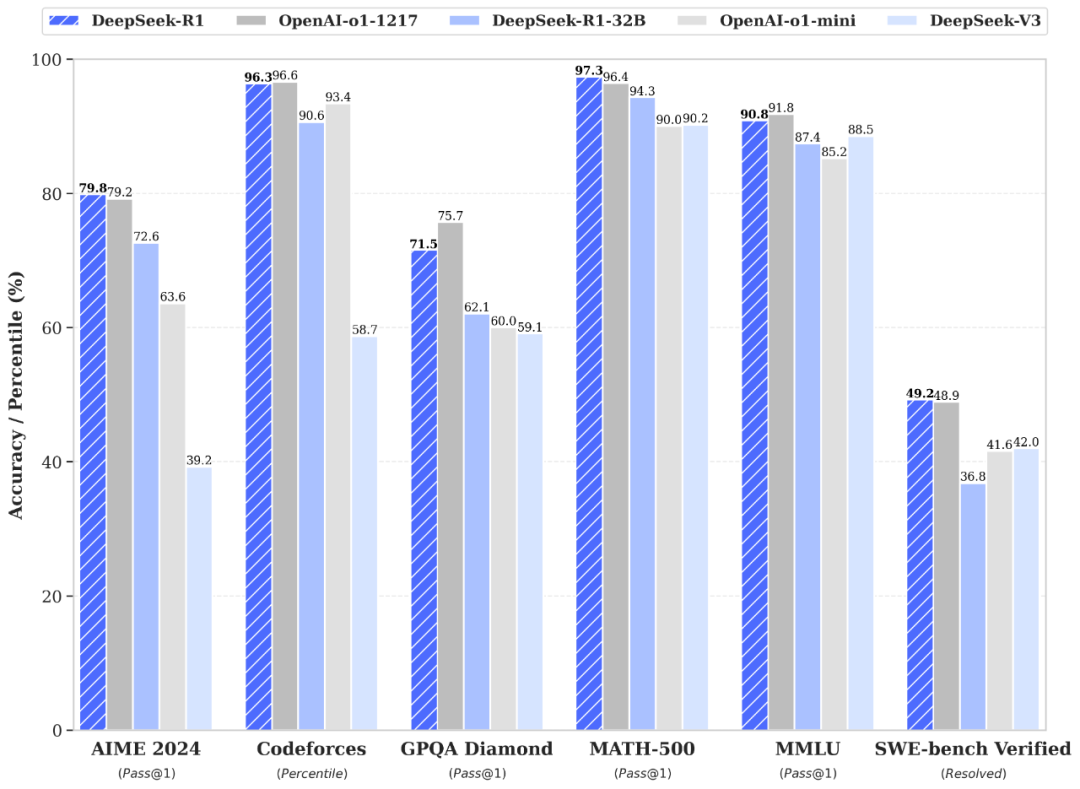
Тести продуктивності DeepSeek
У завданнях з програмування Codeforces R1 отримала 96,3%. Крім того, вона набрала 90,8% за тестом MMLU і 71,5% за GPQA Diamond, продемонструвавши свою універсальність та здатність до міркування в різних галузях. Ці цифри позиціонують R1 як сильну та високопродуктивну альтернативу на конкурентному ринку моделей штучного інтелекту.







Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: